A Velox Primer, Part 1


This is the first part of a series of short articles that will take you through Velox’s internal structures and concepts. In this first part, we will discuss how distributed queries are executed, how data is shuffled among different stages, and present Velox concepts such as Tasks, Splits, Pipelines, Drivers, and Operators that enable such functionality.
Distributed Query Execution
Velox is a library that provides the functions that go into a query fragment in a distributed compute engine. Distributed compute engines, like Presto and Spark run so-called exchange parallel plans. Exchange is also known as a data shuffle, and allows data to flow from one stage to the next. Query fragments are the things connected by shuffles, and comprise the processing that is executed within a single worker node. A shuffle takes input from a set of fragments and routes rows of input to particular consumers based on a characteristic of the data, i.e., a partitioning key. The consumers of the shuffle read from the shuffle and get rows of data from whatever producer, such that the partitioning key of these rows matches the consumer.
Take the following query as an example:
SELECT key, count(*) FROM T GROUP BY key
Suppose it has n leaf fragments that scan different parts of T (the green circles at stage 1). At the end of the leaf fragment, assume there is a shuffle that shuffles the rows based on key. There are m consumer fragments (the yellow circles at stage 2), where each gets a non-overlapping selection of rows based on column key. Each consumer then constructs a hash table keyed on key, where they store a count of how many times the specific value of key has been seen.
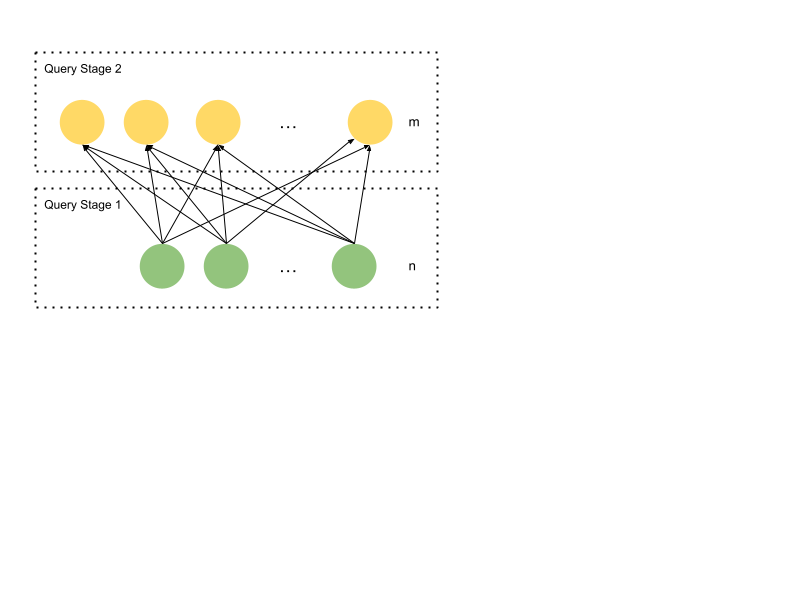
Now, if there are 100B different values of key, the hash table would not conveniently fit on a single machine. For efficiency, there is a point in dividing this into 100 hash tables of 1B entries each. This is the point of exchange parallel scale-out. Think of shuffle as a way for consumers to each consume their own distinct slice of a large stream produced by multiple workers.
Distributed query engines like Presto and Spark both fit the above description. The difference is in, among other things, how they do the shuffle, but we will get back to that later.
Tasks and Splits
Within a worker node, the Velox representation of a query fragment is called a
Task (velox::exec::Task). A task is informed by mainly two things:
- Plan -
velox::core::PlanNode: specifies what the Task does. - Splits -
velox::exec::Split: specifies the data the Task operates on.
The Splits correspond to the plan that the Task is executing. For the first
stage Tasks (table scanning), the Splits specify pieces of files to scan. For
the second stage Tasks (group by), their Splits identify the table scan Tasks
from which the group by reads its input. There are file splits
(velox::connector::ConnectorSplit) and remote splits
(velox::exec::RemoteConnectorSplit). The first identifies data to read, the
second identifies a running Task.
The distributed engine makes PlanNodes and Splits. Velox takes these and makes Tasks. Tasks send back statistics, errors and other status information to the distributed engine.
Pipelines, Drivers and Operators
Inside a Task, there are Pipelines. Each pipeline is a linear sequence of
operators (velox::exec::Operator), and operators are the objects that implement
relational logic. In the case of the group by example, the first task has one
pipeline, with a TableScan (velox::exec::TableScan) and a PartitionedOutput
(velox::exec::PartitionedOutput). The second Task too has one pipeline, with
an Exchange, a LocalExchange, HashAggregation, and a
PartitionedOutput.
Each pipeline has one or more Drivers. A Driver is a container for one linear sequence of Operators, and typically runs on its own thread. The pipeline is the collection of Drivers with the same sequence of Operators. The individual Operator instances belong to each Driver. The Drivers belong to the Task. These are interlinked with smart pointers such that they are kept alive for as long as needed.
An example of a Task with two pipelines is a hash join, with separate pipelines for the build and for the probe side. This makes sense because the build must be complete before the probe can proceed. We will talk more about this later.
The Operators on each Driver communicate with each other through the Driver.
The Driver picks output from one Operator, keeps tabs on stats and passes it to
the next Operator. The data passed between Operators consists of vectors. In
particular, an Operator produces/consumes a RowVector, which is a vector with a
child vector for every column of the relation - it is the equivalent of
RecordBatch in Arrow. All vectors are subclasses of velox::BaseVector.
Operator Sources, Sinks and State
The first Operator in a Driver is called a source. The source operator takes Splits to figure the file/remote Task that provides its data, and produces a sequence of RowVectors. The last operator in the pipeline is called a sink. The sink operator does not produce an output RowVector, but rather puts the data somewhere for a consumer to retrieve. This is typically a PartitionedOutput. The consumer of the PartitionedOutput is an Exchange in a different task, where the Exchange is in the source position. Operators that are neither sources or sinks are things like FilterProject, HashProbe, HashAggregation and so on, more on these later.
Operators also contain a state. They can be blocked, accepting input, have output to produce or not, or may be notified that no more input is coming. Operators do not call the API functions of other Operators directly, but instead the Driver decides which Operator to advance next. This has the benefit that no part of the Driver's state is captured in nested function calls. The Driver has a flat stack and therefore can go on and off thread at any time, without having to unwind and restore nested function frames.
Recap
We have seen how a distributed query consists of fragments joined by shuffles. Each fragment has a Task, which has pipelines, Drivers and Operators. PlanNodes represent what the task is supposed to do. These tell the Task how to set up Drivers and Operators. Splits tell the Task where to find input, e.g. from files or from the other Tasks. A Driver corresponds to a thread of execution. It may be running or blocked, e.g. waiting for data to become available or for its consumer to consume already produced data. Operators pass data between themselves as vectors.
In the next article we will discuss the different stages in the life of a query.