Velox Query Tracing



TL;DR
The query trace tool helps analyze and debug query performance and correctness issues. It helps prevent interference from external noise in a production environment (such as storage, network, etc.) by allowing replay of a part of the query plan and dataset in an isolated environment, such as a local machine. This is much more efficient for query performance analysis and issue debugging, as it eliminates the need to replay the whole query in a production environment.
How Tracing Works
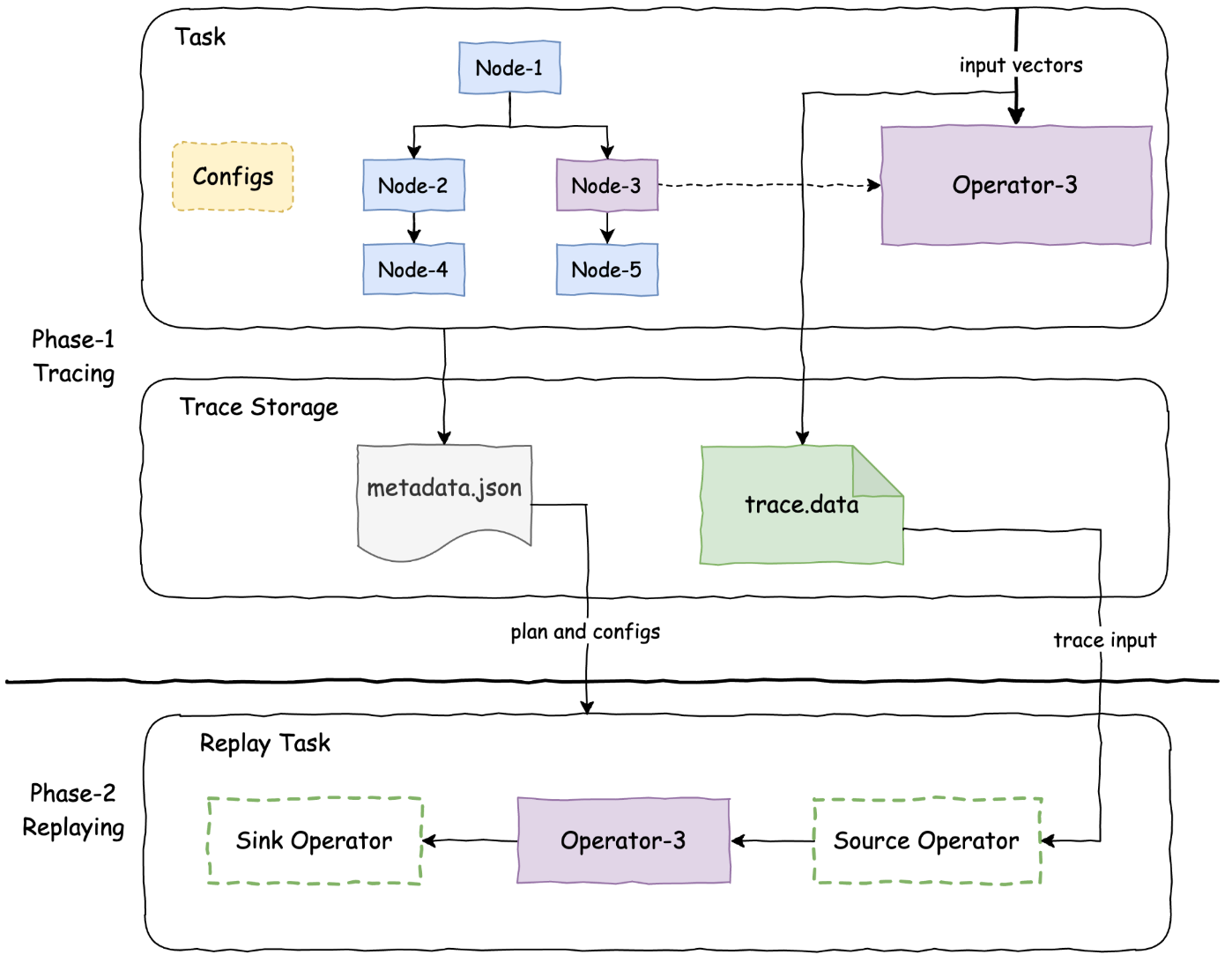
The tracing process consists of two distinct phases: the tracing phase and the replaying phase. The tracing phase is executed within a production environment, while the replaying phase is conducted in a local development environment.
Tracing Phase
- Trace replay required metadata, including the query plan fragment, query configuration, and connector properties, is recorded during the query task initiation.
- Throughout query processing, each traced operator logs the input vectors or splits storing them in a designated storage location.
- The metadata and splits are serialized in JSON format, and the operator data inputs are serialized using a presto serializer.
Replaying Phase
- Read and deserialize the recorded query plan, extract the traced plan node, and assemble a plan fragment with customized source and sink nodes.
- The source node reads the input from the serialized operator inputs on storage and the sink operator prints or logs out the execution stats.
- Build a task with the assembled plan fragment in step 1. Apply the recorded query configuration and connector properties to replay the task with the same input and configuration setup as in production.
NOTE: The presto serialization might lose input vector encoding, such as lazy vector and nested dictionary encoding, which affects the operator’s execution. Hence, it might not always be the same as in production.
Tracing Framework
Trace Writers
There are three types of writers: TaskTraceMetadataWriter, OperatorTraceInputWriter,
and OperatorTraceSplitWriter. They are used in the prod or shadow environment to record
the real execution data.
- The
TaskTraceMetadataWriterrecords the query metadata during task creation, serializes it, and saves it into a file in JSON format. - The
OperatorTraceInputWriterrecords the input vectors from the target operator, it uses a Presto serializer to serialize each vector batch and flush immediately to ensure that replay is possible even if a crash occurs during execution. - The
OperatorTraceSplitWritercaptures the input splits from the targetTableScanoperator. It serializes each split and immediately flushes it to ensure that replay is possible even if a crash occurs during execution.
Storage Location
It is recommended to store traced data in a remote storage system to ensure its preservation and accessibility even if the computation clusters are reconfigured or encounter issues. This also helps prevent nodes in the cluster from failing due to local disk exhaustion.
Users should start by creating a root directory. Writers will then create subdirectories within this root directory to organize the traced data. A well-designed directory structure will keep the data organized and accessible for replay and analysis.
Metadata Location
The TaskTraceMetadataWriter is set up during the task creation so it creates a trace directory
named $rootDir/$queryId/$taskId.
Input Data and Split Location
The node ID consolidates the tracing for the same tracing plan node. The pipeline ID isolates the tracing data between operators created from the same plan node (e.g., HashProbe and HashBuild from the HashJoinNode). The driver ID isolates the tracing data of peer operators in the same pipeline from different drivers.
Correspondingly, to ensure the organized and isolated tracing data storage, the OperatorTraceInputWriter
and OpeartorTraceSplitWriter are set up during the operator initialization and create a data or split
tracing directory in
$rootDir/$queryId$taskId/$nodeId/$pipelineId/$driverId
Memory Management
Add a new leaf system pool named tracePool for tracing memory usage, and expose it
like memory::MemoryManager::getInstance()->tracePool().
Trace Readers
Three types of readers correspond to the query trace writers: TaskTraceMetadataReader,
OperatorTraceInputReader, and OperatorTraceSplitReader. The replayers typically use
them in the local environment, which will be described in detail in the Query Trace Replayer section.
- The
TaskTraceMetadataReadercan load the query metadata JSON file and extract the query configurations, connector properties, and a plan fragment. The replayer uses these to build a replay task. - The
OperatorTraceInputReaderreads and deserializes the input vectors in a tracing data file. It is created and used by aQueryTraceScanoperator which will be described in detail in the Query Trace Scan section. - The
OperatorTraceSplitReaderreads and deserializes the input splits in tracing split info files, and produces a list ofexec::Splitfor the query replay.
Trace Scan
As outlined in the How Tracing Works section, replaying a non-leaf operator requires a
specialized source operator. This operator is responsible for reading data records during the
tracing phase and integrating with Velox’s LocalPlanner with a customized plan node and
operator translator.
TraceScanNode
We introduce a customized ‘TraceScanNode’ to replay a non-leaf operator. This node acts as
the source node and creates a specialized scan operator, known as OperatorTraceScan with
one per driver during the replay. The TraceScanNode contains the trace directory for the
designated trace node, the pipeline ID associated with it, and a driver ID list passed during
the replaying by users so that the OperatorTraceScan can locate the right trace input data or
split directory.
OperatorTraceScan
As described in the Storage Location section, a plan node may be split into multiple pipelines, each pipeline can be divided into multiple operators. Each operator corresponds to a driver, which is a thread of execution. There may be multiple tracing data files for a single plan node, one file per driver.
Query Trace Replayer
The query trace replayer is typically used in the local environment and works as follows:
- Load traced query configurations, connector properties, and a plan fragment.
- Extract the target plan node from the plan fragment using the specified plan node ID.
- Use the target plan node in step 2 to create a replay plan node. Create a replay plan.
- If the target plan node is a
TableScanNode, add the replay plan node to the replay plan as the source node. Get all the traced splits usingOperatorInputSplitReader. Use the splits as inputs for task replaying. - For a non-leaf operator, add a
QueryTraceScanNodeas the source node to the replay plan and then add the replay plan node. - Add a sink node, apply the query configurations (disable tracing), and connector properties, and execute the replay plan.
Detail usage please see the tracing doc in https://facebookincubator.github.io/velox/develop/debugging/tracing.html
Future Work
- Add support for more operators
- Customize the replay task execution instead of AssertQueryBuilder
- Supports IcebergHiveConnector
- Add trace replay for an entire pipeline