Simple Functions: Efficient Complex Types

This blogpost is part of a series of blog posts that discuss different features and optimizations of the simple function interface.
Efficient Complex Types
In this blogpost, we will discuss two major recent changes to the simple function interface to make its performance comparable to the vector function implementations for functions that produce or consume complex types (Arrays, Maps and Rows).
To show how much simpler simple functions are. The figure below shows a function NestedMapSum written in both the simple and vector interfaces. The function consumes a nested map and computes the summations of all values and keys. Note that the vector function implementation is minimal without any special optimization (ex: vector reuse, fast path for flat inputs ..etc). Adding optimizations will make it even longer.

View types for inputs
The previous representations of input complex types in the simple function interface were computationally expensive. Data from vectors used to be copied into std containers and passed to simple functions to process it. Arrays, Maps and Structs used to be materialized into std::vectors, folly::F14FastMap and std::tuples. The graph below illustrates the previous approach.
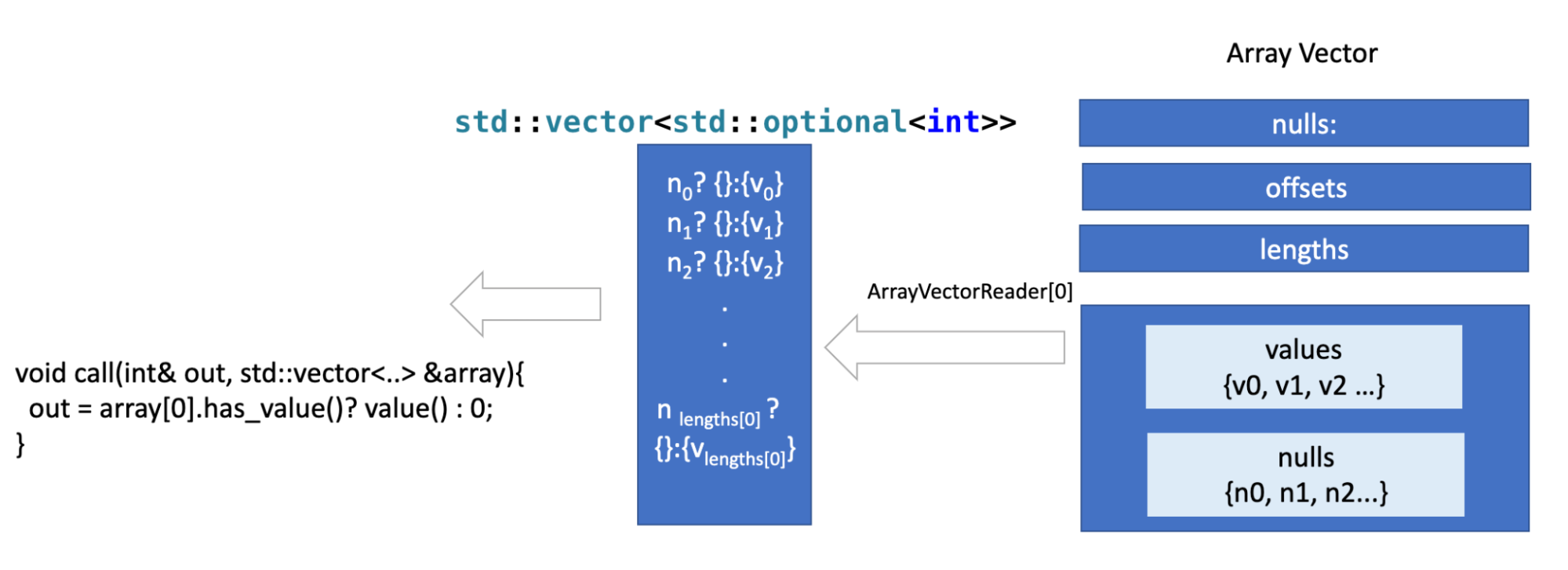
The previous approach has two key inefficiencies; Eager materialization : For each row, all the data in the input vector is decoded and read before calling the function. And Double reading, the data is read twice once when the input is constructed, and again in the function when it's used.
In order to mitigate those regressions, Velox introduced View types: ArrayViews, MapViews ...etc. The goal is to keep the authoring simple but achieve at least the performance of a basic vector implementation that decodes input and applies some logic for every row without any special optimizations.
The view types are Lazy, very cheap to construct and do not materialize the underlying data unless the code accesses it.For example, the function array_first only needs to read the first element in every array, moreover the cardinality function does not need to read any elements in the array. They view types have interfaces similar to those of std::containers.
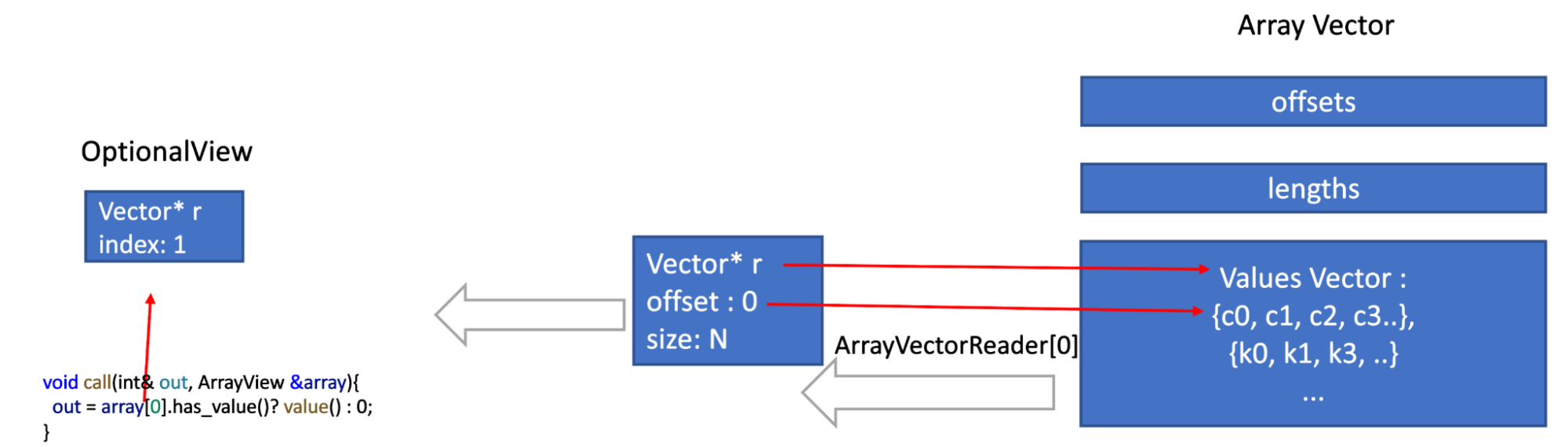
In a simplified form, an ArrayView stores the length and the offset of the array within the vector, in addition to a pointer to the elements array. Only when an element is accessed then an OptionalAccessor is created, which contains the index of the accessed element and a pointer to the containing vector. Only when the user calls value() or has_value() on that accessor then the nullity or the value is read. Other view types are implemented in a similar way, The graph below illustrates the process.
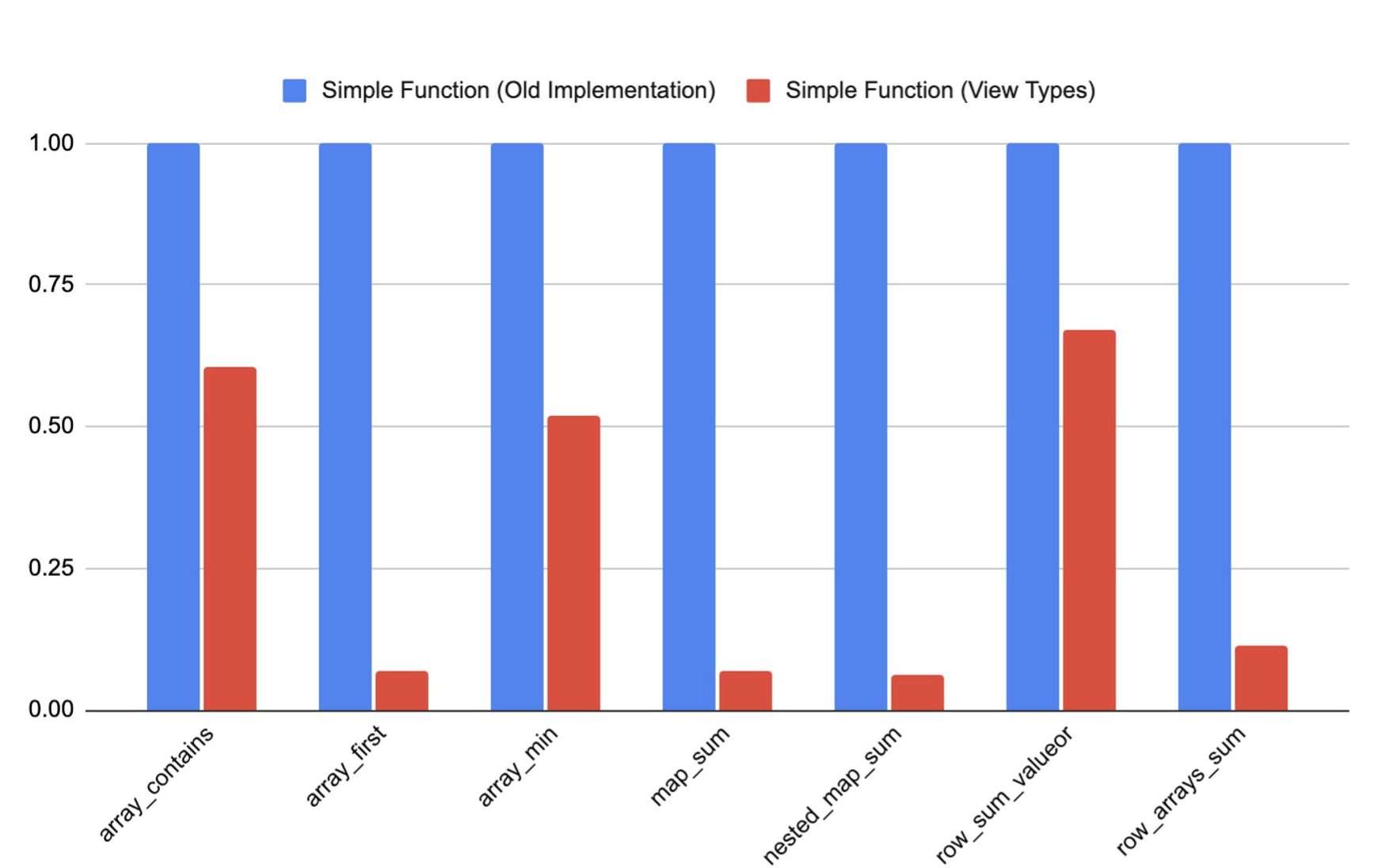
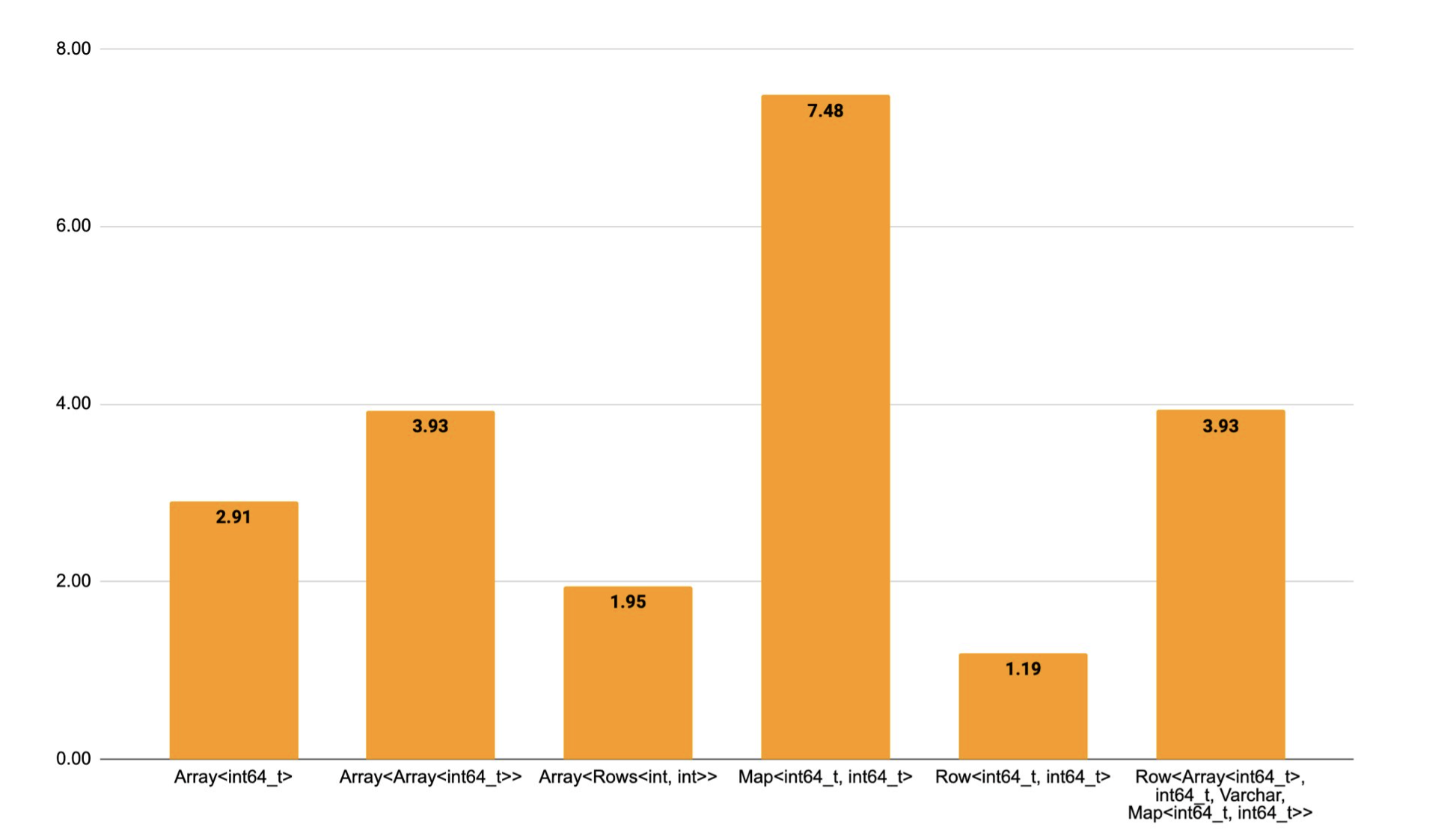
The graph below compares the runtime of some functions written in the simple interface before and after the introduction of the view types. The speedup for arrays is around 2X, for maps the speed is much higher > 10X because materializing the intermediate representation previously involves hashing the elements while constructing the hashmap. Furthermore, the overhead of materialization for nested complex types is very high as well, as reflected in row_arrays_sum.
The graph below compares the runtimes of some functions written using the simple interface, a basic vector function implementation with no special optimizations for the non general case, and a vector implementation that is specialized for flat and null free. The bars are annotated with the line of codes (LOC) used to implement each function.
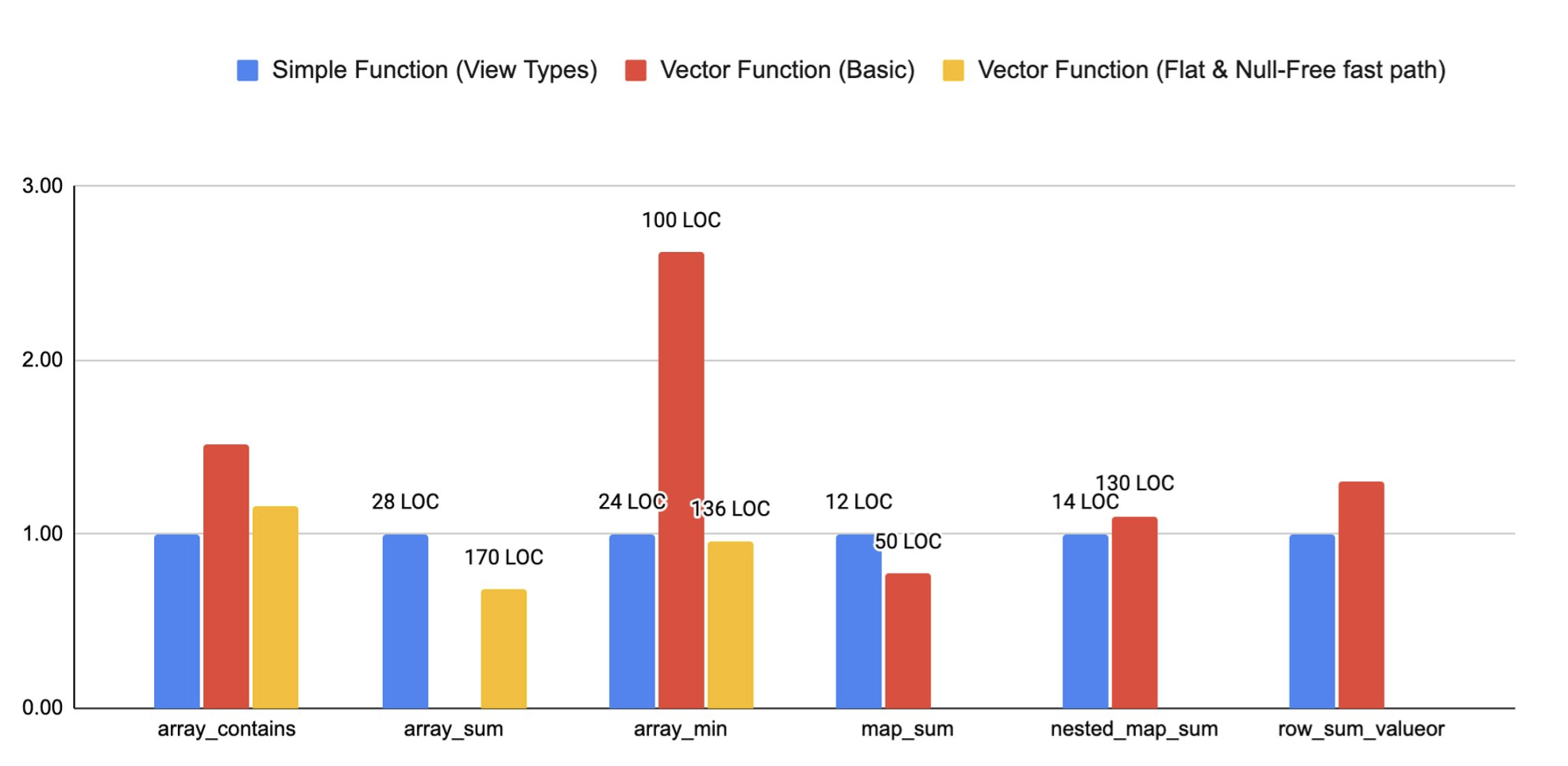
We can see that LOC are significantly lower for simple functions. ArraySum with flat and null free optimization is faster because the summation can be optimized much better when it's performed over a sequential array of data. The reason the simple is faster than the vector for some benchmarks is because we have several optimizations in the simple interface that are not implemented in the basic vector versions.
Writer types for outputs
A similar pattern of inefficiency existed for functions with complex output types. The graph below shows the previous path of writing complex types through the simple function interface. In the previous path, for each row, the result is first written to a temporary object (std::vector, folly::f14FastMap<>, etc.), then serialized into the Velox vector.
We changed the writing path so that the data is written directly into the Velox vector during the function evaluation. By introducing writer types: ArrayWriter, MapWriter, RowWriter. This avoids the double materialization and the unnecessary sorting and hashing for maps.
Consider the function below for example that constructs an array [0, n).

outerArray is an array writer and whenever push_back is called, the underlying vector array is updated directly and a new element is written to it.
In order & final elements writing: Unlike the previous interface, the new writer interface needs to write things in order, since it directly serializes elements into Velox vector buffers. Written elements also can not be modified.
For example, for a function with an Array<Map> output , we can't add three maps, and write to them concurrently. The new interface should enforce that one map is written completely before the next one starts. This is because we are serializing things directly in the map vector, and to determine the offset of the new map we need first to know the end offset of the previous one.
The code below shows a function with Array<Map> output:

Compatibility with std::like containers.: Unfortunately, the new interface is not completely compatible with std::like interfaces, in fact, it deviates syntactically and semantically (for example a std::map enforces unique keys and ordering of elements) while map writer does not. When the element type is primitive (ex: Array<int>) we enable std::like APIs (push_back, emplace()).
But we can not do that for nested complex types (ex:Array<Array<int>>) since it breaks the in-order & final elements writing rule mentioned above.
The figure below shows the performance gain achieved by this change, functions' performance is evaluated before and after the change.
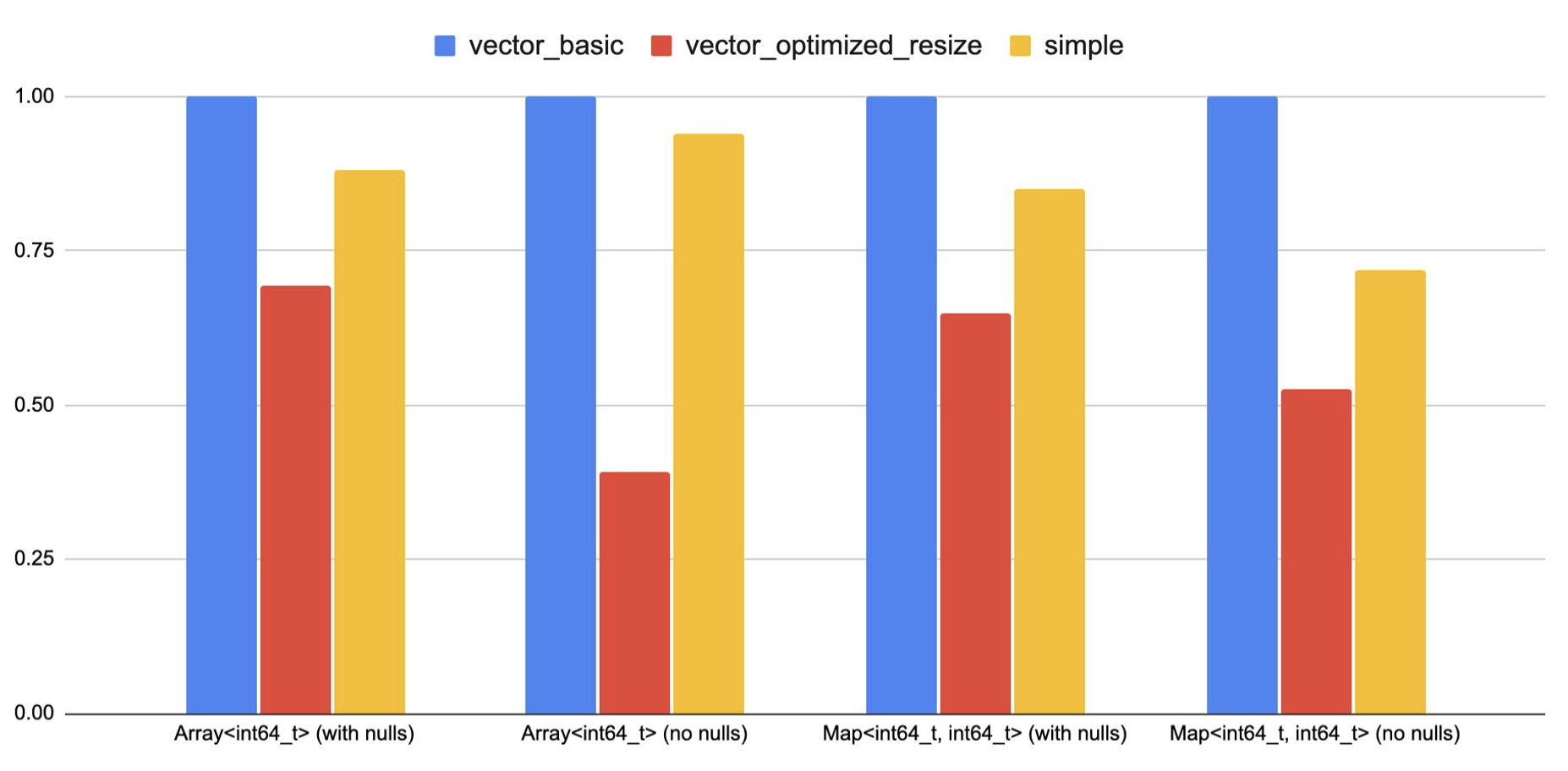
The chart below compares the performance of those functions with vector functions implementations, a vector function with an optimization that precomputes the total size needed for the output vector and a single resize is also added. Note that those functions do almost no computation other than constructing the output map. Hence the resize cost becomes very critical, if those were doing more work, then its effect would be less. Furthermore, the gap indicates that it might be worth it to add a way in the simple interface that enables pre-computing/resizing the output vector size.
Examples:
For full documentation of the view and writer types, APIs, and how to write simple functions follow thelink.