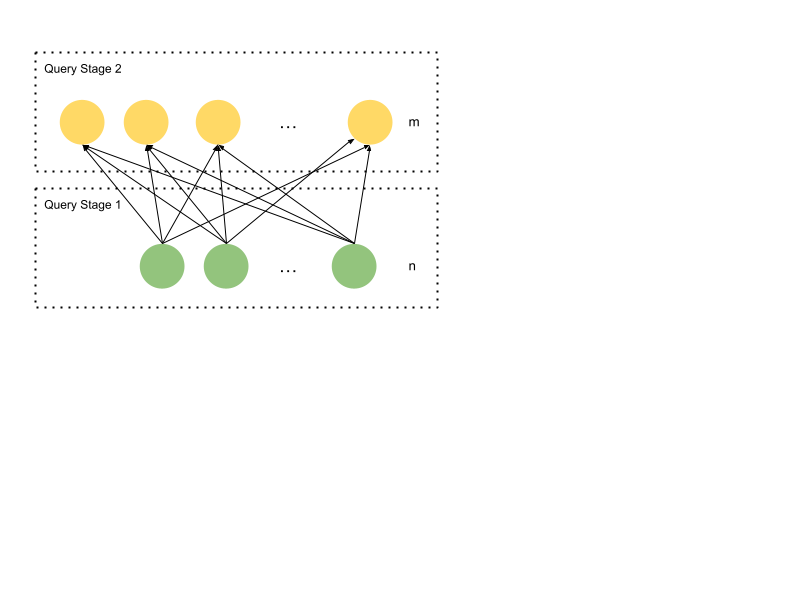Velox depends on several libraries.
Some of these dependencies include open-source libraries from Meta, including Folly and
Facebook Thrift. These libraries are in active development and also depend on each other, so they all have to be updated to the same version at the same time.
Updating these dependencies typically involves modifying the Velox code to align with any public API or semantic changes in these dependencies.
However, a recent upgrade of Folly and Facebook Thrift to version v2025.04.28.00 caused a SEGFAULT only in one unit test in Velox
named velox_functions_remote_client_test.
We immediately put on our gdb gloves and looked at the stack traces. This issue was also reproducible in a debug build.
The SEGFAULT occurred in Facebook Thrift's ThriftServer Class during it's initialization but the offending call was invoking a destructor of a certain handler.
However, the corresponding source code was pointing to an invocation of a different function. And this code was present inside a Facebook Thrift
header called AsyncProcessor.h.
This handler (RemoteServer) was implemented in Velox as a Thrift definition. Velox compiled this thrift file using Facebook Thrift, and the generated code
was using the ServerInterface class in Facebook Thrift. This ServerInterface class was further extended from both the AsyncProcessorFactory and
ServiceHandlerBase interfaces in Facebook Thrift.
One of the culprits resulting in SEGFAULTs in the past was the conflict due to the usage of Apache Thrift and Facebook Thrift.
However, this was not the root cause this time because we were able to reproduce this issue by just building the test without the Apache Thrift dependency installed.
We were entering a new territory to investigate, and we were not sure where to start.
We then compiled an example called EchoService in Facebook Thrift that was very similar to the RemoteServer, and it worked. Then we copied and compiled the Velox RemoteServer
in Facebook Thrift and that worked too! So the culprit was likely in the compilation flags, which likely differed between Facebook Thrift and Velox.
We enabled the verbose logging for both builds and were able to spot one difference. We saw the GCC coroutines flag being used in the Facebook Thrift build.
We were also curious about the invocation of the destructor instead of the actual function. We put our gdb gloves back on and dumped the entire
vtable for the RemoteServer class and its base classes. The vtables were different when it was built in Velox vs. Facebook Thrift.
Specifically, the list of functions inherited from ServiceHandlerBase was different.
The vtable for the RemoteServer handler in the Velox build had the following entries:
Tying up both pieces of evidence, we could conclude that Velox generated a different vtable structure compared to what Facebook Thrift (and thus ThriftServer) was built with.
Looking around further, we noticed that the ServiceHandlerBase was conditionally adding functions based on the coroutines compile flag that influences the FOLLY_HAS_COROUTINES macro from the portability header.
As a result, the ThriftServer would access an incorrect function (~ServiceHandlerBase destructor at offset 3 in the first vtable above) instead of the expected
initialization function (semifuture_onStartServing at offset 3 in the second vtable above), thus resulting in a SEGFAULT.
We recompiled the Facebook Thrift dependency for Velox with the coroutines compile flag disabled, and the test passed.
At the end of the previous
article, we were halfway
through running our first distributed query:
SELECT l_partkey, count(*) FROM lineitem GROUP BY l_partkey;
We discussed how a query starts, how tasks are set up, and the interactions
between plans, operators, and drivers. We have also presented how the first
stage of the query is executed, from table scan to partitioned output - or the
producer side of the shuffle.
In this article, we will discuss the second query stage, or the consumer side
of the shuffle.
As presented in the previous post, on the first query stage each worker reads
the table, then produces a series of information packets (SerializedPages)
intended for different workers of stage 2. In our example, the lineitem table
has no particular physical partitioning or clustering key. This means that any
row of the table can have any value of l_partkey in any of the files forming
the table. So in order to group data based on l_partkey, we first need to make
sure that rows containing the same values for l_partkey are processed by the
same worker – the data shuffle at the end of stage 1.
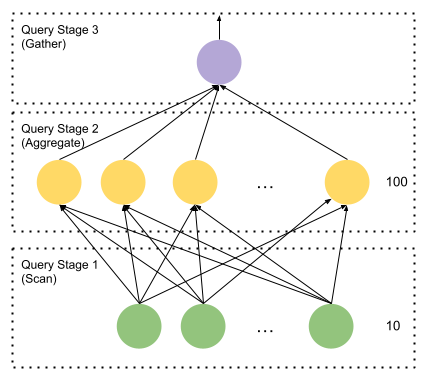
The overall query structure is as follows:
The query coordinator distributes table scan splits to stage 1 workers in no
particular order. The workers process these and, as a side effect, fill
destination buffers that will be consumed by stage 2 workers. Assuming there
are 100 stage 2 workers, every stage 1 Driver has its own PartitionedOutput
which has 100 destinations. When the buffered serializations grow large enough,
these are handed off to the worker's OutputBufferManager.
Now let’s focus on the stage 2 query fragment. Each stage 2 worker has the
following plan fragment: PartitionedOutput over Aggregation over LocalExchange
over Exchange.
Each stage 2 Task corresponds to one destination in the OutputBufferManager of
each stage 1 worker. The first stage 2 Tasks fetches destination zero from all
the stage 1 Tasks. The second stage 2 fetches destination 1 from the first
stage Tasks and so on. Everybody talks to everybody else. The shuffle proceeds
without any central coordination.
But let's zoom in to what actually happens at the start of stage 2.
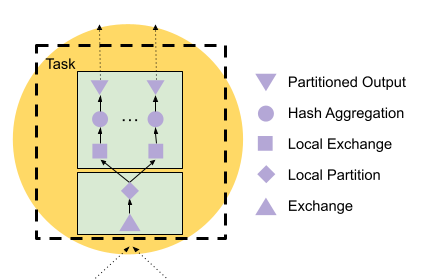
The plan has a LocalExchange node after the Exchange. This becomes two
pipelines: Exchange and LocalPartition on one side, and LocalExchange,
HashAggregation, and PartitionedOutput on the other side.
The Velox Task is intended to be multithreaded, with typically 5 to 30 Drivers.
There can be hundreds of Tasks per stage, thus amounting to thousands of
threads per stage. So, each of the 100 second stage workers is consuming 1/100
of the total output of the first stage. But it is doing this in a multithreaded
manner, with many threads consuming from the ExchangeSource. We will explain
this later.
In order to execute a multithreaded group by, we can either have a thread-safe
hash table or we can partition the data in n disjoint streams, and then proceed
aggregating each stream on its own thread. On a CPU, we almost always prefer to
have threads working on their own memory, so data will be locally partitioned
based on l_partkey using a local exchange. CPUs have complex cache coherence
protocols to give observers a consistent ordered view of memory, so
reconciliation after many cores have written the same cache line is both
mandatory and expensive. Strict memory-to-thread affinity is what makes
multicore scalability work.
To create efficient and independent memory access patterns, the second stage
reshuffles the data using a local exchange. In concept, this is like the remote
exchange between tasks, but is scoped inside the Task. The producer side
(LocalPartition) calculates a hash on the partitioning column l_partkey, and
divides this into one destination per Driver in the consumer pipeline. The
consumer pipeline has a source operator LocalExchange that reads from the queue
filled by LocalPartition. See
LocalPartition.h
for details. Also see the code in
Task.cpp
for setting up the queues between local exchange producers and consumers.
While remote shuffles work with serialized data, local exchanges pass in-memory
vectors between threads. This is also the first time we encounter the notion of
using columnar encodings to accelerate vectorized execution. Velox became known
by its extensive use of such techniques, which we call compressed execution. In
this instance, we use dictionaries to slice vectors across multiple
destinations – we will discuss it next.
Query execution often requires changes to the cardinality (number of rows in a
result) of the data. This is essentially what filters and joins do – they
either reduce the cardinality of the data, e.g., filters or selective joins, or
increase the cardinality of the data, e.g. joins with multiple key matches.
Repartitioning in LocalPartition assigns a destination to each row of the input
based on the partitioning key. It then makes a vector for each destination with
just the rows for that destination. Suppose rows 2, 8 and 100 of the current
input hash to 1. Then the vector for destination 1 would only have rows 2, 8
and 100 from the original input. We could make a vector of three rows by
copying the data. Instead, we save the copy by wrapping each column of the
original input in a DictionaryVector with length 3 and indices 2, 8 and 100.
This is much more efficient than copying, especially for wide and nested data.
Later on, the LocalExchange consumer thread running destination 1 will see a
DictionaryVector of 3 rows. When this is accessed by the HashAggregation
Operator, the aggregation sees a dictionary and will then take the indirection
and will access for row 0 the value at 2 in the base (inner) vector, for row 1
the value at 8, and so forth. The consumer for destination 0 does the exact
same thing but will access, for example, rows 4, 9 and 50.
The base of the dictionaries is the same on all the consumer threads. Each
consumer thread just looks at a different subset. The cores read the same cache
lines, but because the base is not written to (read-only), there is no
cache-coherence overhead.
To summarize, a DictionaryVector<T> is a wrapper around any vector of T. The
DictionaryVector specifies indices, which give indices into the base vector.
Dictionary encoding is typically used when there are few distinct values in a
column. Take the strings “experiment” and “baseline”. If a column only has
these values, it is far more efficient to represent it as a vector with
“experiment” at 0 and “baseline” at 1, and a DictionaryVector that has,
say, 1000 elements, where these are either the index 0 or 1.
Besides this, DictionaryVectors can also be used to denote a subset or a
reordering of elements of the base. Because all places that accept vectors also
accept DictionaryVectors, the DictionaryVector becomes the universal way of
representing selection. This is a central precept of Velox and other modern
vectorized engines. We will often come across this concept.
We have now arrived at the second pipeline of stage 2. It begins with
LocalExchange, which then feeds into HashAggregation. The LocalExchange picks a
fraction of the Task's input specific to its local destination, about
1/number-of-drivers of the task's input.
We will talk about hash tables, their specific layout and other tricks in a
later post. For now, we look at HashAggregation as a black box. This specific
aggregation is a final aggregation, which is a full pipeline barrier that only
produces output after all input is received.
How does the aggregation know it has received all its input? Let's trace the
progress of the completion signal through the shuffles. A leaf worker knows
that it is at end if the Task has received the “no more splits” message in the
last task update from the coordinator.
So, if one DataSource inside a tableScan is at end and there are no more
splits, this particular TableScan is not blocked and it is at end. This will
have the Driver call PartitionedOutput::noMoreInput() on the tableScan's
PartitionedOutput. This will cause any buffered data for any destination to get
flushed and moved over to OutputBufferManager with a note that no more is
coming. OutputBufferManager knows how many Drivers there are in the TableScan
pipeline. After it has received this many “no more data coming” messages, it
can tell all destinations that this Task will generate no more data for them.
Now, when stage 2 tasks query stage 1 producers, they will know that they are
at end when all the producers have signalled that there is no more data coming.
The response to the get data for destination request has a flag identifying the
last batch. The ExchangeSource on the stage 2 Task set the no-more-data flag.
This is then queried by all the Drivers and each of the Exchange Operators sees
this. This then calls noMoreInput in the LocalPartition. This queues up a “no
more data” signal in the local exchange queues. If the LocalExchange at the
start of the second pipeline of stage 2 sees a “no more data” from each of its
sources, then it is at end and noMoreInput is called on the HashAggregation.
This is how the end of data propagates. Up until now, HashAggregation has
produced no output, since the counts are not known until all input is received.
Now, HashAggregation starts producing batches of output, which contain the
l_partkey value and the number of times this has been seen. This reaches the
last PartitionedOutput, which in this case has only one destination, the final
worker that produces the result set. This will be at end when all the 100
sources have reported their own end of data.
We have finally walked through the distributed execution of a simple query. We
presented how data is partitioned between workers in the cluster, and then a
second time over inside each worker.
Velox and Presto are designed to aggressively parallelize execution, which
means creating distinct, non-overlapping sets of data to process on each
thread. The more threads, the more throughput. Also remember that for CPU
threads to be effective, they must process tasks that are large enough (often
over 100 microseconds worth of cpu time), and not communicate too much with
other threads or write to memory other threads are writing to. This is
accomplished with local exchanges.
Another important thing to remember from this article is how columnar encodings
(DictionaryVectors, in particular) can be used as a zero-copy way of
representing selection/reorder/duplication. We will see this pattern again with
filters, joins, and other relational operations.
Next we will be looking at joins, filters, and hash aggregations. Stay tuned!
In this article, we will discuss how a distributed compute engine executes a
query similar to the one presented in
our first article:
SELECT l_partkey, count(*) FROM lineitem GROUP BY l_partkey;
We use the TPC-H schema to illustrate the example, and
Prestissimo
as the compute engine orchestrating distributed query execution. Prestissimo is
responsible for the query engine frontend (parsing, resolving metadata,
planning, optimizing) and distributed execution (allocating resources and
shipping query fragments), and Velox is responsible for the execution of plan
fragments within a single worker node. Throughout this article, we will present
which functions are performed by Velox and which by the distributed engine -
Prestissimo, in this example.
Prestissimo first receives the query through a coordinator node, which is
responsible for parsing and planning the query. For our sample query, a
distributed query plan with three query fragments will be created:
The first fragment reads the l_partkey column from the lineitem table and
divides its output according to a hash of l_partkey.
The second fragment reads the output from the first fragment and updates a
hash table from l_partkey containing the number of times the particular value
of l_partkey has been seen (the count(*) aggregate function implementation).
The final fragment then reads the content of the hash tables, once the
second fragment has received all the rows from the first fragment.
The shuffle between the two first fragments partitions the data according to
l_partkey. Suppose there are 100 instances of the second fragment. If the hash
of l_partkey modulo 100 is 0, the row goes to the first task in the second
stage; if it is 1, the row goes to the second task, and so forth. In this way,
each second stage Task gets a distinct subset of the rows. The shuffle between
the second and third stage is a gather, meaning that there is one Task in the
third stage that will read the output of all 100 tasks in the second stage.
A Stage is the set of Tasks that share the same plan fragment. A Task is the
main integration point between Prestissimo and Velox; it’s the Velox execution
instance that physically processes all or part of the data that passes through
the stage.
To set up the distributed execution, Prestissimo first selects the workers from
the pool of Prestissimo server processes it manages. Assuming that stage 1 is
10 workers wide, it selects 10 server processes and sends the first stage plan
to them. It then selects 100 workers for stage 2 and sends the second stage
plan to these. The last stage that gathers the result has only one worker, so
Prestissimo sends the final plan to only one worker. The set of workers for
each stage may overlap, so a single worker process may host multiple stages of
one query.
Let's now look more closely at what each worker does at query setup time.
In Prestissimo, the message that sets up a Task in a worker is called Task
Update. A Task Update has the following information: the plan, configuration
settings, and an optional list of splits. Splits are further qualified by what
plan node they are intended for, and whether more splits for the recipient plan
node and split group will be coming.
Since split generation involves enumerating files from storage (so they may
take a while), Presto allows splits to be sent to workers asynchronously, such
that the generation of splits can run in parallel with the execution of the
first splits. Therefore, the first task update specifies the plan and the
config. Subsequent ones only add more splits.
Besides the plan, the coordinator provides configs as maps from string key to
string value, both top level and connector level. The connector configs have
settings for each connector; connectors are used by table scan and table writer
to deal with storage and file formats. These configs and other information,
like thread pools, top level memory pool etc. are handed to the Task in a
QueryCtx object. See velox/core/QueryCtx.h in the Velox repo for details.
Once the Velox Task is created, a TaskManager hands it splits to work on. This
is done with Task::addSplit(), and can be done after the Task has started
executing. See velox/exec/Task.h for details.
Let's zoom into what happens at Task creation: A PlanNode tree specifying what
the Task does is given to the Task as part of a PlanFragment. The most
important step done at Task creation is splitting the plan tree into pipelines.
Each pipeline then gets a DriverFactory, which is the factory class that makes
Drivers for the pipeline. The Drivers, in their turn, contain the Operators
that do the work of running the query. The DriverFactories are made in
LocalPlanner.cpp. See LocalPlanner::plan for details.
Following the execution model known as Volcano, the plan is represented by an
operator tree where each node consumes the output of its child operators, and
returns output to the parent operator. The root node is typically a
PartitionedOutputNode or a TableWriteNode. The leaf nodes are either
TableScanNode, ExchangeNode or ValuesNode (used for query literals). The full
set of Velox PlanNode can be found at velox/core/PlanNode.h.
The PlanNodes mostly correspond to Operators. PlanNodes are not executable as
such; they are only a structure describing how to make Drivers and Operators,
which do the actual execution. If the tree of nodes has a single branch, then
the plan is a single pipeline. If it has nodes with more than one child
(input), then the second input of the node becomes a separate pipeline.
Task::start() creates the DriverFactories, which then create the Drivers. To
start execution, the Drivers are queued on a thread pool executor. The main
function that runs Operators is Driver::runInternal(). See this function for
the details of how Operators and the Driver interface: Operator::isBlocked()
determines if the Driver can advance. If it cannot, it goes off thread until a
future is realized, which then puts it back on the executor.
getOutput() retrieves data from an Operator and addInputs() feeds data into
another Operator. The order of execution is to advance the last Operator which
can produce output and then feed this to the next Operator. if an Operator
cannot produce output, then getOutput() is called on the Operator before it
until one is found that can produce data. If no operator is blocked and no
Operator can produce output, then the plan is at end. The noMoreInput() method
is called on each operator. This can unblock production of results, for
example, an OrderBy can only produce its output after it knows that it has all
the input.
The Minimal Pipeline: Table Scan and Repartitioning
Table Scan. With the table scan stage of our sample query, we have one pipeline
with two operators: TableScan and PartitionedOutput. Assume this pipeline has
five Drivers, and that all these five Drivers go on the thread pool executor.
The PartitionedOutput cannot do anything because it has no input. The
TableScan::getOutput() is then called. See velox/exec/TableScan.cpp for
details. The first action TableScan takes is to look for a Split with
task::getSplitOrFuture(). If there is no split available, this returns a
future. The Driver will then park itself off thread and install a callback on
the future that will reschedule the Driver when a split is available.
It could also be the case that there is no split and the Task has been notified
that no more splits will be coming. In this case TableScan would be at the end.
Finally, if a Split is available, TableScan interprets it. Given a TableHandle
specification provided as part of the plan (list of columns and filters), the
Connector (as specified in the Split) makes a DataSource. The DataSource
handles the details of IO and file and table formats.
The DataSource is then given the split. After this, DataSource::next() can be
called repeatedly to get vectors (batches) of output from the file/section of
file specified by the Split. If the DataSource is at the end, TableScan looks
for the next split. See Connector.h for the Connector and DataSource
interfaces.
Repartitioning. Now we have traced execution up to the TableScan returning its
first batch of output. The Driver feeds this to PartitionedOutput::addInput().
See PartitionedOutput.cpp for details. PartitionedOutput first calculates a
hash on the partitioning key, in this case, l_partkey, producing a destination
number for each row in the batch RowVectorPtr input_.
Each destination has a partly filled serialization buffer (VectorStreamGroup)
for each destination worker. If there are 100 Tasks in the second stage, each
PartitionedOutput has 100 destinations, each with one VectorStreamGroup. The
main function of a VectorStreamGroup is append(), which takes a RowVectorPtr
and a set of row numbers in it. It serializes each value identified by the row
numbers and adds it to the partly formed serialization. When enough rows are
accumulated in the VectorStreamGroup, it produces a SerializedPage. See flush()
in PartitionedOutput.cpp.
The SerializedPage is a self contained serialized packet of information that
can be transmitted over the wire to the next stage. Each such page only
contains rows intended for the same recipient. These pages are then queued up
in the worker process' OutputBufferManager. Note the code with BlockingReason
in flush(). The buffer manager maintains separate queues of all consumers of
all Tasks. If a queue is full, adding output may block. This returns a future
that is realized when there is space to add more data to the queue. This
depends on when the Task's consumer Task fetches the data.
Shuffles in Prestissimo are implemented by PartitionedOutput at the producer
and Exchange at the consumer end. The OutputBufferManager keeps ready
serialized data for consumers to pick up. The binding of these to the Presto
wire protocols is in TaskManager.cpp for the producer side, and in
PrestoExchangeSource.cpp for the consumer side.
We presented how a plan becomes executable and how data moves between and
inside Operators. We discussed that a Driver can block (go off thread) to wait
for a Split to become available, or to wait for its output to be consumed. We
have now scratched the surface of running a leaf stage of a distributed query.
There is much more to Operators and vectors, though. In the next installment of
Velox Primer, we will look at what the second stage of our minimal sample query
does.
This is the first part of a series of short articles that will take you through
Velox’s internal structures and concepts. In this first part, we will discuss
how distributed queries are executed, how data is shuffled among different
stages, and present Velox concepts such as Tasks, Splits, Pipelines, Drivers,
and Operators that enable such functionality.
Velox is a library that provides the functions that go into a query fragment in
a distributed compute engine. Distributed compute engines, like Presto and
Spark run so-called exchange parallel plans. Exchange is also known as a data
shuffle, and allows data to flow from one stage to the next. Query fragments
are the things connected by shuffles, and comprise the processing that is
executed within a single worker node. A shuffle takes input from a set of
fragments and routes rows of input to particular consumers based on a
characteristic of the data, i.e., a partitioning key. The consumers of the
shuffle read from the shuffle and get rows of data from whatever producer, such
that the partitioning key of these rows matches the consumer.
Take the following query as an example:
SELECT key, count(*) FROM T GROUP BY key
Suppose it has n leaf fragments that scan different parts of T (the
green circles at stage 1). At the end of the leaf fragment, assume there is a
shuffle that shuffles the rows based on key. There are m consumer fragments
(the yellow circles at stage 2), where each gets a non-overlapping selection of
rows based on column key. Each consumer then constructs a hash table keyed
on key, where they store a count of how many times the specific value of
key has been seen.
Now, if there are 100B different values of key, the hash table would not
conveniently fit on a single machine. For efficiency, there is a point in
dividing this into 100 hash tables of 1B entries each. This is the point of
exchange parallel scale-out. Think of shuffle as a way for consumers to each
consume their own distinct slice of a large stream produced by multiple
workers.
Distributed query engines like Presto and Spark both fit the above description.
The difference is in, among other things, how they do the shuffle, but we will
get back to that later.
Within a worker node, the Velox representation of a query fragment is called a
Task (velox::exec::Task). A task is informed by mainly two things:
Plan - velox::core::PlanNode: specifies what the Task does.
Splits - velox::exec::Split: specifies the data the Task operates on.
The Splits correspond to the plan that the Task is executing. For the first
stage Tasks (table scanning), the Splits specify pieces of files to scan. For
the second stage Tasks (group by), their Splits identify the table scan Tasks
from which the group by reads its input. There are file splits
(velox::connector::ConnectorSplit) and remote splits
(velox::exec::RemoteConnectorSplit). The first identifies data to read, the
second identifies a running Task.
The distributed engine makes PlanNodes and Splits. Velox takes these and makes
Tasks. Tasks send back statistics, errors and other status information to the
distributed engine.
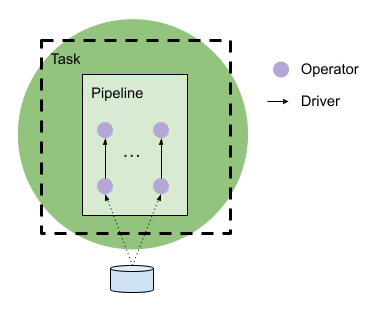
Inside a Task, there are Pipelines. Each pipeline is a linear sequence of
operators (velox::exec::Operator), and operators are the objects that implement
relational logic. In the case of the group by example, the first task has one
pipeline, with a TableScan (velox::exec::TableScan) and a PartitionedOutput
(velox::exec::PartitionedOutput). The second Task too has one pipeline, with
an Exchange, a LocalExchange, HashAggregation, and a
PartitionedOutput.
Each pipeline has one or more Drivers. A Driver is a container for one linear
sequence of Operators, and typically runs on its own thread. The pipeline is
the collection of Drivers with the same sequence of Operators. The individual
Operator instances belong to each Driver. The Drivers belong to the Task. These
are interlinked with smart pointers such that they are kept alive for as long as
needed.
An example of a Task with two pipelines is a hash join, with separate pipelines
for the build and for the probe side. This makes sense because the build must
be complete before the probe can proceed. We will talk more about this later.
The Operators on each Driver communicate with each other through the Driver.
The Driver picks output from one Operator, keeps tabs on stats and passes it to
the next Operator. The data passed between Operators consists of vectors. In
particular, an Operator produces/consumes a RowVector, which is a vector with a
child vector for every column of the relation - it is the equivalent of
RecordBatch in Arrow. All vectors are subclasses of velox::BaseVector.
The first Operator in a Driver is called a source. The source operator takes
Splits to figure the file/remote Task that provides its data, and produces a
sequence of RowVectors. The last operator in the pipeline is called a sink. The
sink operator does not produce an output RowVector, but rather puts the data
somewhere for a consumer to retrieve. This is typically a PartitionedOutput.
The consumer of the PartitionedOutput is an Exchange in a different task, where
the Exchange is in the source position. Operators that are neither sources or
sinks are things like FilterProject, HashProbe, HashAggregation and so on, more
on these later.
Operators also contain a state. They can be blocked, accepting input, have
output to produce or not, or may be notified that no more input is coming.
Operators do not call the API functions of other Operators directly, but
instead the Driver decides which Operator to advance next. This has the benefit
that no part of the Driver's state is captured in nested function calls. The
Driver has a flat stack and therefore can go on and off thread at any time,
without having to unwind and restore nested function frames.
We have seen how a distributed query consists of fragments joined by shuffles.
Each fragment has a Task, which has pipelines, Drivers and Operators. PlanNodes
represent what the task is supposed to do. These tell the Task how to set up
Drivers and Operators. Splits tell the Task where to find input, e.g. from
files or from the other Tasks. A Driver corresponds to a thread of execution.
It may be running or blocked, e.g. waiting for data to become available or for
its consumer to consume already produced data. Operators pass data between
themselves as vectors.
In the next article we will discuss the different stages in the life of a query.
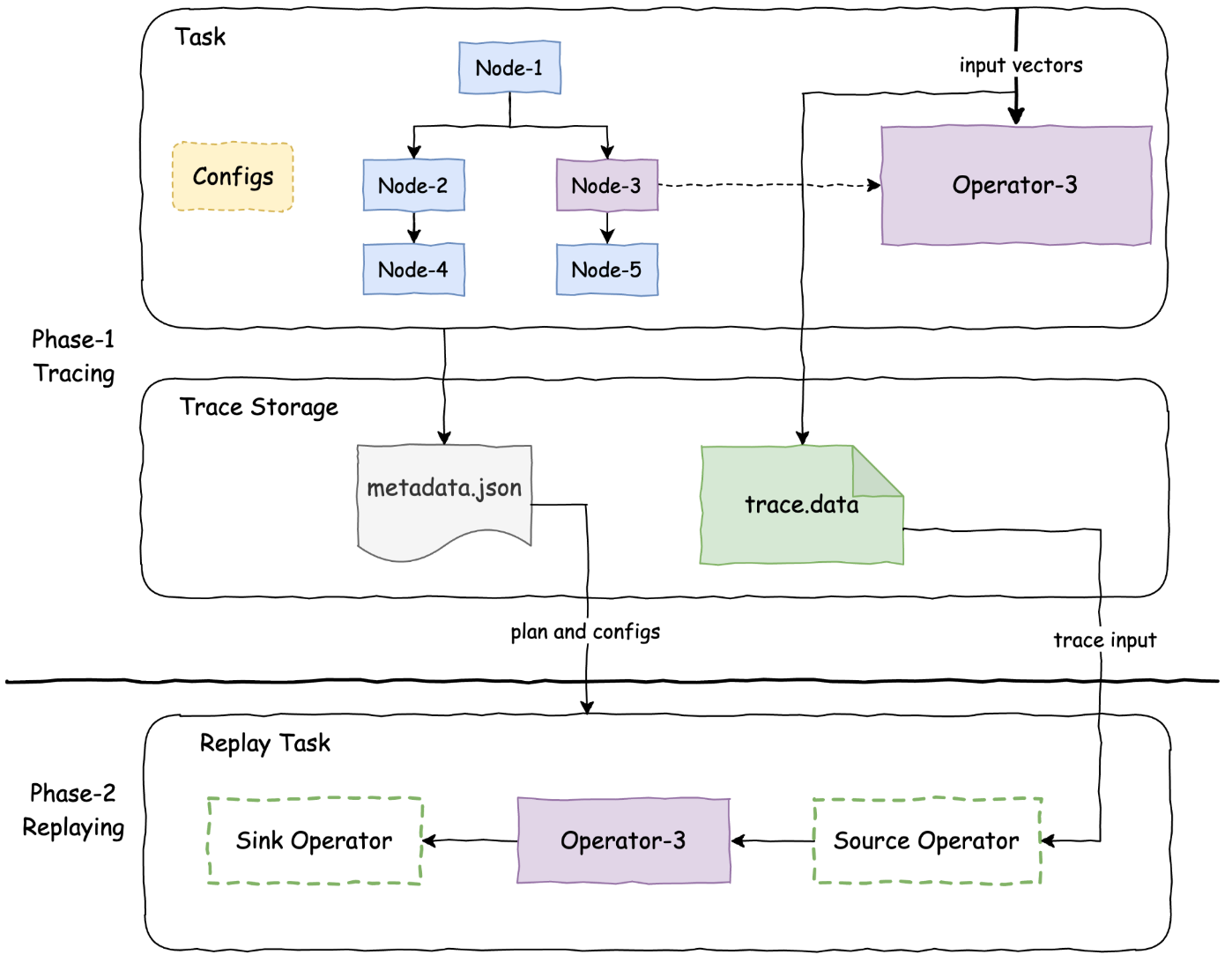
The query trace tool helps analyze and debug query performance and correctness issues. It helps prevent
interference from external noise in a production environment (such as storage, network, etc.) by allowing
replay of a part of the query plan and dataset in an isolated environment, such as a local machine.
This is much more efficient for query performance analysis and issue debugging, as it eliminates the need
to replay the whole query in a production environment.
The tracing process consists of two distinct phases: the tracing phase and the replaying phase. The
tracing phase is executed within a production environment, while the replaying phase is conducted in
a local development environment.
Tracing Phase
Trace replay required metadata, including the query plan fragment, query configuration,
and connector properties, is recorded during the query task initiation.
Throughout query processing, each traced operator logs the input vectors or splits
storing them in a designated storage location.
The metadata and splits are serialized in JSON format, and the operator data inputs are
serialized using a presto serializer.
Replaying Phase
Read and deserialize the recorded query plan, extract the traced plan node, and assemble a plan
fragment with customized source and sink nodes.
The source node reads the input from the serialized operator inputs on storage and the sink operator
prints or logs out the execution stats.
Build a task with the assembled plan fragment in step 1. Apply the recorded query configuration and
connector properties to replay the task with the same input and configuration setup as in production.
NOTE: The presto serialization might lose input vector encoding, such as lazy vector and nested dictionary
encoding, which affects the operator’s execution. Hence, it might not always be the same as in production.
There are three types of writers: TaskTraceMetadataWriter, OperatorTraceInputWriter,
and OperatorTraceSplitWriter. They are used in the prod or shadow environment to record
the real execution data.
The TaskTraceMetadataWriter records the query metadata during task creation, serializes it,
and saves it into a file in JSON format.
The OperatorTraceInputWriter records the input vectors from the target operator, it uses a Presto
serializer to serialize each vector batch and flush immediately to ensure that replay is possible
even if a crash occurs during execution.
The OperatorTraceSplitWriter captures the input splits from the target TableScan operator. It
serializes each split and immediately flushes it to ensure that replay is possible even if a crash
occurs during execution.
It is recommended to store traced data in a remote storage system to ensure its preservation and
accessibility even if the computation clusters are reconfigured or encounter issues. This also
helps prevent nodes in the cluster from failing due to local disk exhaustion.
Users should start by creating a root directory. Writers will then create subdirectories within
this root directory to organize the traced data. A well-designed directory structure will keep
the data organized and accessible for replay and analysis.
Metadata Location
The TaskTraceMetadataWriter is set up during the task creation so it creates a trace directory
named $rootDir/$queryId/$taskId.
Input Data and Split Location
The node ID consolidates the tracing for the same tracing plan node. The pipeline ID isolates the
tracing data between operators created from the same plan node (e.g., HashProbe and HashBuild from
the HashJoinNode). The driver ID isolates the tracing data of peer operators in the same pipeline
from different drivers.
Correspondingly, to ensure the organized and isolated tracing data storage, the OperatorTraceInputWriter
and OpeartorTraceSplitWriter are set up during the operator initialization and create a data or split
tracing directory in
Three types of readers correspond to the query trace writers: TaskTraceMetadataReader,
OperatorTraceInputReader, and OperatorTraceSplitReader. The replayers typically use
them in the local environment, which will be described in detail in the Query Trace Replayer section.
The TaskTraceMetadataReader can load the query metadata JSON file and extract the query
configurations, connector properties, and a plan fragment. The replayer uses these to build
a replay task.
The OperatorTraceInputReader reads and deserializes the input vectors in a tracing data file.
It is created and used by a QueryTraceScan operator which will be described in detail in
the Query Trace Scan section.
The OperatorTraceSplitReader reads and deserializes the input splits in tracing split info files,
and produces a list of exec::Split for the query replay.
As outlined in the How Tracing Works section, replaying a non-leaf operator requires a
specialized source operator. This operator is responsible for reading data records during the
tracing phase and integrating with Velox’s LocalPlanner with a customized plan node and
operator translator.
TraceScanNode
We introduce a customized ‘TraceScanNode’ to replay a non-leaf operator. This node acts as
the source node and creates a specialized scan operator, known as OperatorTraceScan with
one per driver during the replay. The TraceScanNode contains the trace directory for the
designated trace node, the pipeline ID associated with it, and a driver ID list passed during
the replaying by users so that the OperatorTraceScan can locate the right trace input data or
split directory.
OperatorTraceScan
As described in the Storage Location section, a plan node may be split into multiple pipelines,
each pipeline can be divided into multiple operators. Each operator corresponds to a driver, which
is a thread of execution. There may be multiple tracing data files for a single plan node, one file
per driver.
The query trace replayer is typically used in the local environment and works as follows:
Load traced query configurations, connector properties,
and a plan fragment.
Extract the target plan node from the plan fragment using the specified plan node ID.
Use the target plan node in step 2 to create a replay plan node. Create a replay plan.
If the target plan node is a TableScanNode, add the replay plan node to the replay plan
as the source node. Get all the traced splits using OperatorInputSplitReader.
Use the splits as inputs for task replaying.
For a non-leaf operator, add a QueryTraceScanNode as the source node to the replay plan and
then add the replay plan node.
Add a sink node, apply the query configurations (disable tracing), and connector properties,
and execute the replay plan.
In late 2023, the Meta OSS (Open Source Software) Team requested all Meta teams to move the CI deployments from CircleCI to Github Actions. Voltron Data and Meta in collaboration migrated all the deployed Velox CI jobs. For the year 2024, Velox CI spend was on track to overshoot the allocated resources by a considerable amount of money. As part of this migration effort, the CI workloads were consolidated and optimized by Q2 2024, bringing down the projected 2024 CI spend by 51%.
Continuous Integration (CI) is crucial for Velox’s success as an open source project as it helps protect from bugs and errors, reduces likelihood of conflicts and leads to increased community trust in the project. This is to ensure the Velox builds works well on a myriad of system architectures, operating systems and compilers - along with the ones used internally at Meta. The OSS build version of Velox also supports additional features that aren't used internally in Meta (for example, support for Cloud blob stores, etc.).
When a pull request is submitted to Velox, the following jobs are executed:
Linting and Formatting workflows:
Header checks
License checks
Basic Linters
Ensure Velox builds on various platforms
MacOS (Intel, M1)
Linux (Ubuntu/Centos)
Ensure Velox builds under its various configurations
Debug / Release builds
Build default Velox build
Build Velox with support for Parquet, Arrow and External Adapters (S3/HDFS/GCS etc.)
PyVelox builds
Run prerequisite tests
Unit Tests
Benchmarking Tests
Conbench is used to store and compare results, and also alert users on regressions
Various Fuzzer Tests (Expression / Aggregation/ Exchange / Join etc)
Signature Check and Biased Fuzzer Tests ( Expression / Aggregation)
Fuzzer Tests using Presto as source of truth
Docker Image build jobs
If an underlying dependency is changed, a new Docker CI image is built for
Ubuntu Linux
Centos
Presto Linux image
Documentation build and publish Job
If underlying documentation is changed, Velox documentation pages are rebuilt and published
Previous implementation of CI in CircleCI grew organically and was unoptimized, resulting in long build times, and also significantly costlier. This opportunity to migrate to Github Actions helped to take a holistic view of CI deployments and actively optimized to reduce build times and CI spend. Note however, that there has been continued investment in reducing test times to further improve Velox reliability, stability and developer experience. Some of the optimizations completed are:
Persisting build artifacts across builds: During every build, the object files and binaries produced are cached. In addition to this, artifacts such as scalar function signatures and aggregate function signatures are produced. These signatures are used to compare with the baseline version, by comparing against the changes in the current PR to determine if the current changes are backwards incompatible or bias the newly added changes. Using a stash to persist these artifacts helps save one build cycle.
Optimizing our Instances: Building Velox is Memory and CPU intensive job. Some beefy instances (16-core machines) are used to build Velox. After the build, the build artifacts are copied to smaller instances (4 core machines) to run fuzzer tests and other jobs. Since these fuzzers often run for an hour and are less intensive than the build process, it resulted in significant CI savings while increasing the test coverage.
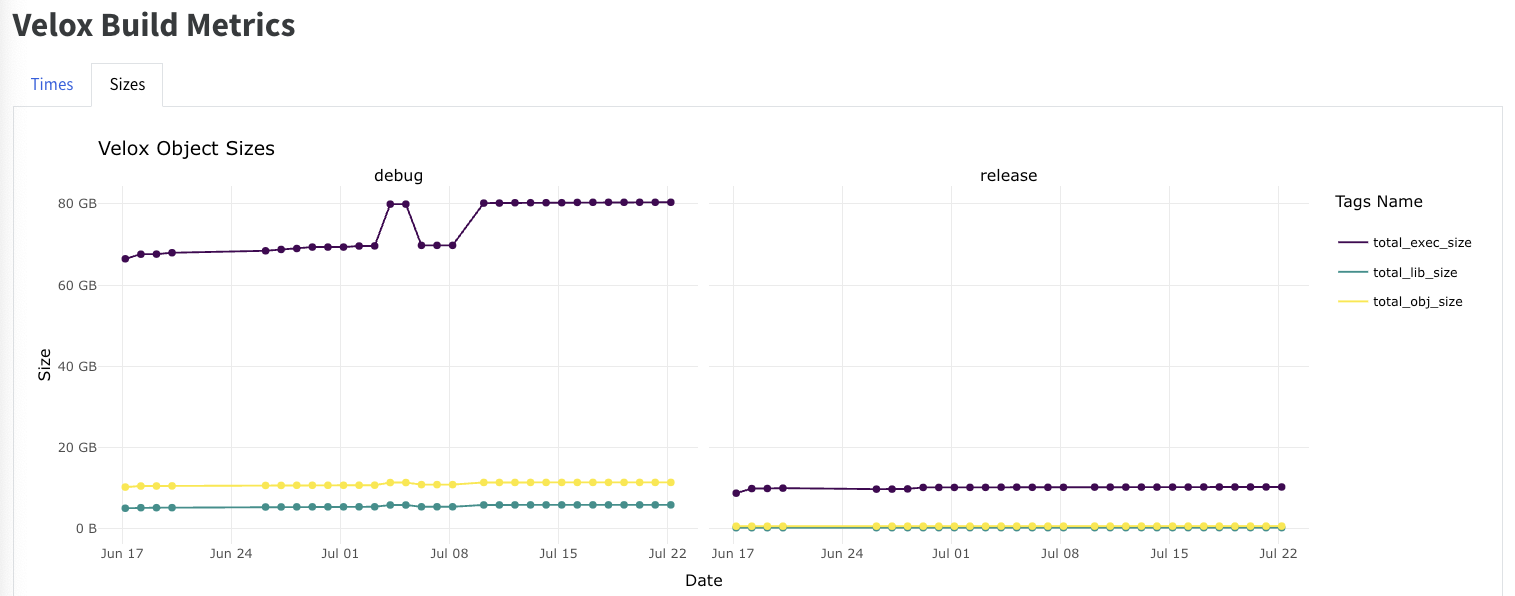
Velox CI builds were instrumented in Conbench so that it can capture various metrics about the builds:
Build times at translation unit / library/ project level.
Binary sizes produced at TLU/ .a,.so / executable level.
Memory pressure
Measure across time how our changes affect binary sizes
A nightly job is run to capture these build metrics and it is uploaded to Conbench. Velox build metrics report is available here: Velox Build Metrics Report
A large part of the credit goes to Jacob Wujciak and the team at Voltron Data. We would also like to thank other collaborators in the Open Source Community and at Meta, including but not limited to:
Meta: Sridhar Anumandla, Pedro Eugenio Rocha Pedreira, Deepak Majeti, Meta OSS Team, and others
Voltron Data: Jacob Wujciak, Austin Dickey, Marcus Hanwell, Sri Nadukudy, and others
Queries that use TRY or TRY_CAST may experience poor performance and high CPU
usage due to excessive exception throwing. We optimized CAST to indicate
failure without throwing and introduced a mechanism for scalar functions to do
the same. Microbenchmark measuring worst case performance of CAST improved
100x. Samples of production queries show 30x cpu time improvement.
TRY construct can be applied to any expression to suppress errors and turn them
into NULL results. TRY_CAST is a version of CAST that suppresses errors and
returns NULL instead.
For example, parse_datetime('2024-05-', 'YYYY-MM-DD') fails:
Invalid format: "2024-05-" is too short
, but TRY(parse_datetime('2024-05-', 'YYYY-MM-DD')) succeeds and returns NULL.
Similarly, CAST('foo' AS INTEGER) fails:
Cannot cast 'foo' to INT
, but TRY_CAST('foo' AS INTEGER) succeeds and returns NULL.
TRY can wrap any expression, so one can wrap CAST as well:
TRY(CAST('foo' AS INTEGER))
Wrapping CAST in TRY is similar to TRY_CAST, but not equivalent. TRY_CAST
suppresses only cast errors, while TRY suppresses any error in the expression
tree.
For example, CAST(1/0 AS VARCHAR) fails:
Division by zero
, TRY_CAST(1/0 AS VARCHAR) also fails:
Division by zero
, but TRY(CAST(1/0 AS VARCHAR)) succeeds and returns NULL.
In this case, the error is generated by division operation (1/0). TRY_CAST
cannot suppress that error, but TRY can. More generally, TRY(CAST(...))
suppresses all errors in all expressions that are evaluated to produce
an input for CAST as well as errors in CAST itself, but TRY_CAST suppresses
errors in CAST only.
In most cases only a fraction of rows generates an error. However, there are
queries where a large percentage of rows fail. In these cases, a lot of CPU
time goes into handling exceptions.
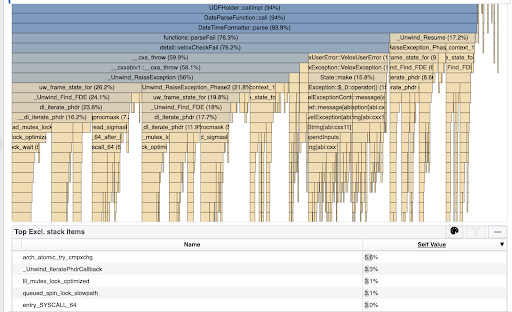
For example, one Prestissimo query used 3 weeks of CPU time, 93% of
which was spent processing try(date_parse(...)) expressions where most rows
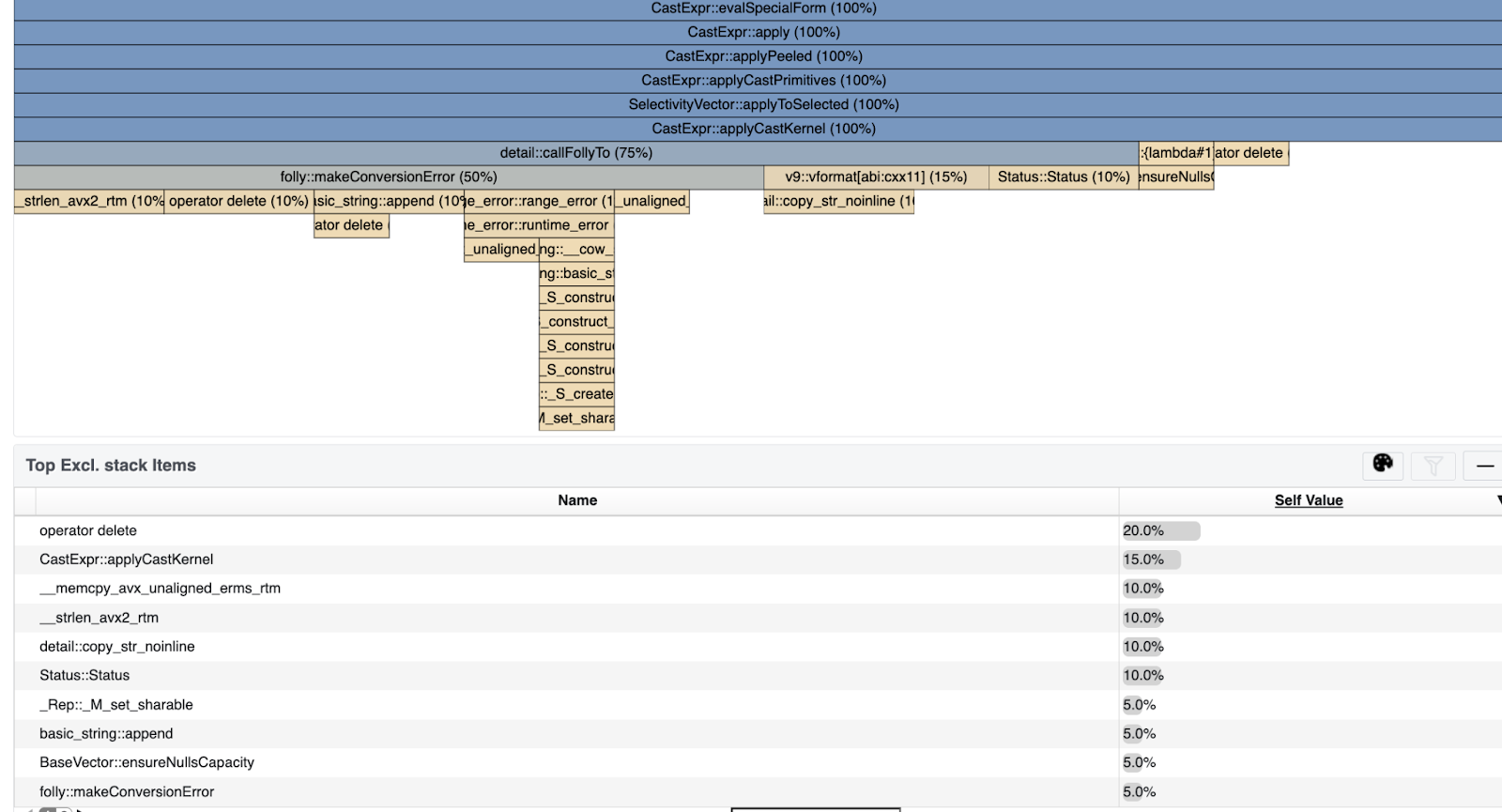
failed. Here is a profile for that query that shows that all the time went into
stack unwinding:
This query processes 14B rows, ~70% of which fail in date_parse(...) function
due to the date string being empty.
presto> select try(date_parse('', '%Y-%m-%d')); _col0 ------- NULL (1 row) – TRY suppressed Invalid format: "" error and produced a NULL.
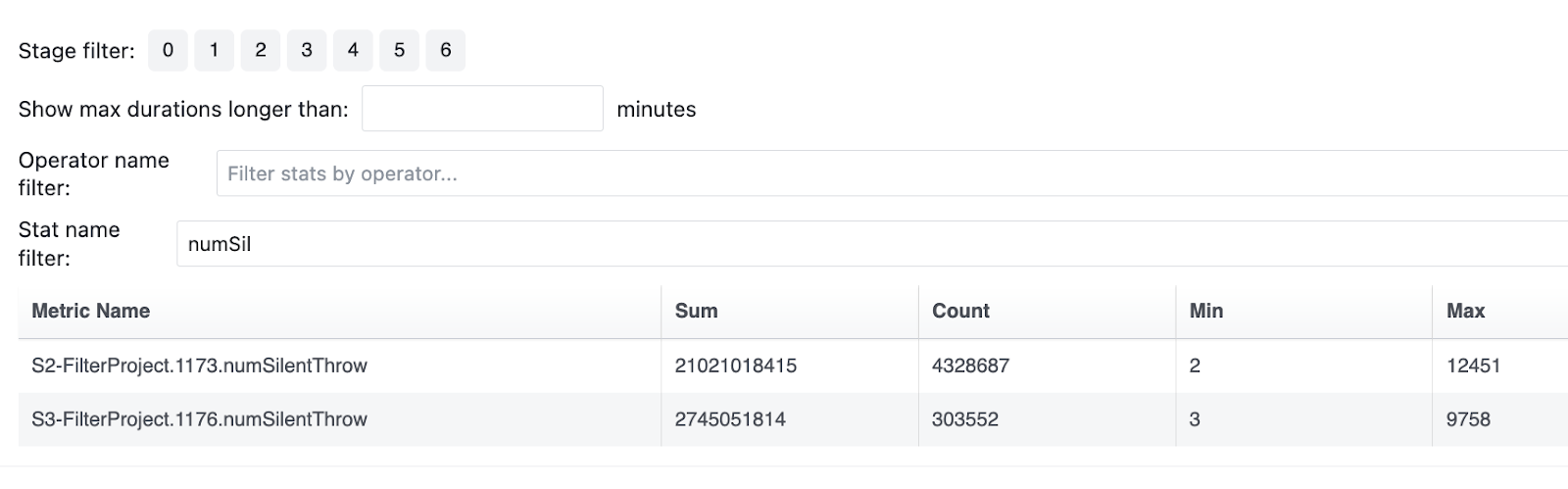
Velox tracks the number of suppressed exceptions per operator / plan node and
reports these as numSilentThrow runtime stat. For this query, Velox reported
21B throws for a single FilterProject node that processed 14B rows. Before the
optimizations, each failing row used to throw twice. An earlier blog post
from Laith Sakka explains why.
After the optimizations this query’s CPU time dropped
to 17h: 30x difference from the original cpu time. Compared to
Presto Java, this query uses 4x less cpu time (originally it used 6x more).
We observed similar issues with queries that use other functions that parse
strings as well as casts from strings.
To avoid the performance penalty of throwing exceptions we need to report errors
differently. Google’s Abseil library uses absl::Status to return errors from
void functions and absl::StatusOr to return value or error from non-void
functions. Arrow library
has similar Status and Result. Our own Folly has folly::Expected.
Inspired by these examples we introduced velox::Status and velox::Expected.
velox::Status holds a generic error code and an error message.
velox::Expected<T> is a typedef for folly::Expected<T, velox::Status>.
For example, a non-throwing modulo operation can be implemented like this:
Expected<int> mod(int a, int b) { if (b == 0) { return folly::makeUnexpected(Status::UserError(“Division by zero”)); } return a % b; }
We extended the Simple Function API to allow authoring non-throwing scalar
functions. The function author can now define a ‘call’ method that returns
Status. Such a function can indicate an error by returning a non-OK status.
Status call(result&, arg1, arg2,..)
These functions are still allowed to throw and exceptions will be handled
properly, but not throwing improves performance of expressions that use TRY.
Modulo SQL function would look like this:
template <typename TExec> struct NoThrowModFunction { VELOX_DEFINE_FUNCTION_TYPES(TExec); Status call(int64_t& result, const int64_t& a, const int64_t& b) { if (b == 0) { return Status::UserError("Division by zero"); } result = a % b; return Status::OK(); } };
We changed date_parse, parse_datetime, and from_iso8601_date Presto functions
to use the new API and report errors without throwing.
Vector functions can implement non-throwing behavior by leveraging the new
EvalCtx::setStatus(row, status) API. However, nowadays we expect virtually all
functions to be written using Simple Function API.
CAST is complex. A single name refers to multiple dozen individual operations.
The full matrix of supported conversions is available in the Velox
documentation. Not all casts throw. For example, cast from an integer to a
string does not throw. However, casts from strings may fail in multiple ways. A
common failure scenario is cast from an empty string. Laith Sakka optimized
this use case earlier.
> select cast('' as integer); Cannot cast '' to INT
However, we are also seeing failures in casting non-empty strings and NaN floating point values to integers.
> select cast(nan() as bigint); Unable to cast NaN to bigint > select cast('123x' as integer); Cannot cast '123x' to INT
CAST from string to integer and floating point value is implemented using
folly::to template. Luckily there is a non-throwing version: folly::tryTo.
We changed our CAST implementation to use folly::tryTo to avoid throwing.
Not throwing helped improve performance of TRY_CAST by 20x.
Still, the profile showed that there is room for further improvement.
After switching to non-throwing implementation, the profile showed that half the
cpu time went into folly::makeConversionError. folly::tryTo returns result or
ConversionCode enum. CAST uses folly::makeConversionError to convert
ConversionCode into a user-friendly error message. This involves allocating and
populating a string for the error message, copying it into the std::range_error
object, then copying it again into Status. This error message is very helpful
if it is being propagated all the way to the user, but it is not needed if the
error is suppressed via TRY or TRY_CAST.
To solve this problem we introduced a thread-local flag, threadSkipErrorDetails,
that indicates whether Status needs to include a detailed error message or not.
By default, this flag is ‘false’, but TRY and TRY_CAST set it to ‘true’. CAST
logic checks this flag to decide whether to call folly::makeConversionError or
not. This change gives a 3x performance boost to TRY_CAST and 2x
to TRY.
After this optimization, we observed that TRY(CAST(...)) is up to 5x slower than
TRY_CAST when many rows fail.
The profile revealed that 30% of cpu time went to
EvalCtx::ensureErrorsVectorSize. For every row that fails, we call
EvalCtx::ensureErrorsVectorSize to resize the error vector to accommodate that
row. When many rows fail we end up resizing a lot: resize(1), resize(2),
resize(3),...resize(n). We fixed this by pre-allocating the error vector in the TRY
expression.
Another 30% of cpu time went into managing reference counts for
std::shared_ptr<std::exception_ptr> stored in the errors vector. We do not need
error details for TRY, hence, no need to store these values. We fixed this by
making error values in error vector optional and updating EvalCtx::setStatus to
skip writing these under TRY.
After all these optimizations, the microbenchmark that measures performance of
casting invalid strings into integers showed 100x improvement. The benchmark
evaluates 4 expressions:
We can identify queries with a high percentage of numSilentThrow rows and
change throwing functions to not throw.
For simple functions this involves changing the ‘call’ method to return Status
and replacing ‘throw’ statements with return Status::UserError(...). You get
extra points for producing error messages conditionally based on thread-local
flag threadSkipErrorDetails().
template <typename TExec> struct NoThrowModFunction { VELOX_DEFINE_FUNCTION_TYPES(TExec); Status call(int64_t& result, const int64_t& a, const int64_t& b) { if (b == 0) { If (threadSkipErrorDetails()) { return Status::UserError(); } return Status::UserError("Division by zero"); } result = a % b; return Status::OK(); } };
We are changing CAST(varchar AS date) to not throw.
We provided a non-throwing ‘call’ API for simple functions that never return a
NULL for a non-NULL input. This covers the majority of Presto functions. For
completeness, we would want to provide non-throwing ‘call’ APIs for all other
use cases:
bool call() for returning NULL sometimes
callAscii for processing all-ASCII inputs
callNullable for processing possibly NULL inputs
callNullFree for processing complex inputs with all NULLs removed.
LIKE is a very useful SQL operator.
It is used to do string pattern matching. The following examples for LIKE usage are from the Presto doc:
SELECT * FROM (VALUES ('abc'), ('bcd'), ('cde')) AS t (name) WHERE name LIKE '%b%' --returns 'abc' and 'bcd' SELECT * FROM (VALUES ('abc'), ('bcd'), ('cde')) AS t (name) WHERE name LIKE '_b%' --returns 'abc' SELECT * FROM (VALUES ('a_c'), ('_cd'), ('cde')) AS t (name) WHERE name LIKE '%#_%' ESCAPE '#' --returns 'a_c' and '_cd'
These examples show the basic usage of LIKE:
Use % to match zero or more characters.
Use _ to match exactly one character.
If we need to match % and _ literally, we can specify an escape char to escape them.
When we use Velox as the backend to evaluate Presto's query, LIKE operation is translated
into Velox's function call, e.g. name LIKE '%b%' is translated to
like(name, '%b%'). Internally Velox converts the pattern string into a regular
expression and then uses regular expression library RE2
to do the pattern matching. RE2 is a very good regular expression library. It is fast
and safe, which gives Velox LIKE function a good performance. But some popularly used simple patterns
can be optimized using direct simple C++ string functions instead of regex.
e.g. Pattern hello% matches inputs that start with hello, which can be implemented by direct memory
comparison of prefix ('hello' in this case) bytes of input:
// Match the first 'length' characters of string 'input' and prefix pattern. bool matchPrefixPattern( StringView input, const std::string& pattern, size_t length) { return input.size() >= length && std::memcmp(input.data(), pattern.data(), length) == 0; }
It is much faster than using RE2. Benchmark shows it gives us a 750x speedup. We can do similar
optimizations for some other patterns:
%hello: matches inputs that end with hello. It can be optimized by direct memory comparison of suffix bytes of the inputs.
%hello%: matches inputs that contain hello. It can be optimized by using std::string_view::find to check whether inputs contain hello.
These simple patterns are straightforward to optimize. There are some more relaxed patterns that
are not so straightforward:
hello_velox%: matches inputs that start with 'hello', followed by any character, then followed by 'velox'.
%hello_velox: matches inputs that end with 'hello', followed by any character, then followed by 'velox'.
%hello_velox%: matches inputs that contain both 'hello' and 'velox', and there is a single character separating them.
Although these patterns look similar to previous ones, but they are not so straightforward
to optimize, _ here matches any single character, we can not simply use memory comparison to
do the matching. And if user's input is not pure ASCII, _ might match more than one byte which
makes the implementation even more complex. Also note that the above patterns are just for
illustrative purpose. Actual patterns can be more complex. e.g. h_e_l_l_o, so trivial algorithm
will not work.
We optimized these patterns as follows. First, we split the patterns into a list of sub patterns, e.g.
hello_velox% is split into sub-patterns: hello, _, velox, %, because there is
a % at the end, we determine it as a kRelaxedPrefix pattern, which means we need to do some prefix
matching, but it is not a trivial prefix matching, we need to match three sub-patterns:
kLiteralString: hello
kSingleCharWildcard: _
kLiteralString: velox
For kLiteralString we simply do a memory comparison:
Note that since it is a memory comparison, it handles both pure ASCII inputs and inputs that
contain Unicode characters.
Matching _ is more complex considering that there are variable length multi-bytes character in
unicode inputs. Fortunately there are existing libraries which provides unicode related operations: utf8proc.
It provides functions that tells us whether a byte in input is the start of a character or not,
how many bytes current character consists of etc. So to match a sequence of _ our algorithm is:
if (subPattern.kind == SubPatternKind::kSingleCharWildcard) { // Match every single char wildcard. for (auto i = 0; i < subPattern.length; i++) { if (cursor >= input.size()) { return false; } auto numBytes = unicodeCharLength(input.data() + cursor); cursor += numBytes; } }
Here:
cursor is the index in the input we are trying to match.
unicodeCharLength is a function which wraps utf8proc function to determine how many bytes current character consists of.
So the logic is basically repeatedly calculate size of current character and skip it.
It seems not that complex, but we should note that this logic is not effective for pure ASCII input.
Every character is one byte in pure ASCII input. So to match a sequence of _, we don't need to calculate the size
of each character and compare in a for-loop. In fact, we don't need to explicitly match _ for pure ASCII input as well.
We can use the following logic instead:
It only matches the kLiteralString pattern at the right position of the inputs, _ is automatically
matched(actually skipped). No need to match it explicitly. With this optimization we get 40x speedup
for kRelaxedPrefix patterns, 100x speedup for kRelaxedSuffix patterns.
Thank you Maria Basmanova for spending a lot of time
reviewing the code.
Reduce_agg
is the only lambda aggregate Presto function. It allows users to define arbitrary aggregation
logic using 2 lambda functions.
reduce_agg(inputValue T, initialState S, inputFunction(S, T, S), combineFunction(S, S, S)) → S Reduces all non-NULL input values into a single value. inputFunction will be invoked for each non-NULL input value. If all inputs are NULL, the result is NULL. In addition to taking the input value, inputFunction takes the current state, initially initialState, and returns the new state. combineFunction will be invoked to combine two states into a new state. The final state is returned. Throws an error if initialState is NULL or inputFunction or combineFunction returns a NULL.
Once can think of reduce_agg as using inputFunction to implement partial aggregation and
combineFunction to implement final aggregation. Partial aggregation processes a list of
input values and produces an intermediate state:
auto s = initialState; for (auto x : input) { s = inputFunction(s, x); } return s;
Final aggregation processes a list of intermediate states and computes the final state.
auto s = intermediates[0]; for (auto i = 1; i < intermediates.size(); ++i) s = combineFunction(s, intermediates[i]); } return s;
For example, one can implement SUM aggregation using reduce_agg as follows:
reduce_agg(c, 0, (s, x) -> s + x, (s, s2) -> s + s2)
Implementation of AVG aggregation is a bit trickier. For AVG, state is a tuple of sum and
count. Hence, reduce_agg can be used to compute (sum, count) pair, but it cannot compute
the actual average. One needs to apply a scalar function on top of reduce_agg to get the
average.
SELECT id, sum_and_count.sum / sum_and_count.count FROM ( SELECT id, reduce_agg(value, CAST(row(0, 0) AS row(sum double, count bigint)), (s, x) -> CAST(row(s.sum + x, s.count + 1) AS row(sum double, count bigint)), (s, s2) -> CAST(row(s.sum + s2.sum, s.count + s2.count) AS row(sum double, count bigint))) AS sum_and_count FROM t GROUP BY id );
The examples of using reduce_agg to compute SUM and AVG are for illustrative purposes.
One should not use reduce_agg if a specialized aggregation function is available.
One use case for reduce_agg we see in production is to compute a product of input values.
reduce_agg(c, 1.0, (s, x) -> s * x, (s, s2) -> s * s2)
Another example is to compute a list of top N distinct values from all input arrays.
reduce_agg(x, array[], (a, b) -> slice(reverse(array_sort(array_distinct(concat(a, b)))), 1, 1000), (a, b) -> slice(reverse(array_sort(array_distinct(concat(a, b)))), 1, 1000))
Note that this is equivalent to the following query:
SELECT array_agg(v) FROM ( SELECT DISTINCT v FROM t, UNNEST(x) AS u(v) ORDER BY v DESC LIMIT 1000 )
Efficient implementation of reduce_agg lambda function is not straightforward. Let’s
consider the logic for partial aggregation.
auto s = initialState; for (auto x : input) { s = inputFunction(s, x); }
This is a data-dependent loop, i.e. the next loop iteration depends on the results of
the previous iteration. inputFunction needs to be invoked on each input value x
separately. Since inputFunction is a user-defined lambda, invoking inputFunction means
evaluating an expression. And since expression evaluation in Velox is optimized for
processing large batches of values at a time, evaluating expressions on one value at
a time is very inefficient. To optimize the implementation of reduce_agg we need to
reduce the number of times we evaluate user-defined lambdas and increase the number
of values we process each time.
One approach is to
convert all input values into states by evaluating inputFunction(initialState, x);
split states into pairs and evaluate combineFunction on all pairs;
repeat step (2) until we have only one state left.
Let’s say we have 1024 values to process. Step 1 evaluates inputFunction expression
on 1024 values at once. Step 2 evaluates combineFunction on 512 pairs, then on 256
pairs, then on 128 pairs, 64, 32, 16, 8, 4, 2, finally producing a single state.
Step 2 evaluates combineFunction 9 times. In total, this implementation evaluates
user-defined expressions 10 times on multiple values each time. This is a lot more
efficient than the original implementation that evaluates user-defined expressions
1024 times.
In general, given N inputs, the original implementation evaluates expressions N times
while the new one log2(N) times.
Note that in case when N is not a power of two, splitting states into pairs may leave
an extra state. For example, splitting 11 states produces 5 pairs + one extra state.
In this case, we set aside the extra state, evaluate combineFunction on 5 pairs, then
bring extra state back to a total of 6 states and continue.
A benchmark, velox/functions/prestosql/aggregates/benchmarks/ReduceAgg.cpp, shows that
initial implementation of reduce_agg is 60x slower than SUM, while the optimized
implementation is only 3x slower. A specialized aggregation function will always be
more efficient than generic reduce_agg, hence, reduce_agg should be used only when
specialized aggregation function is not available.
Finally, a side effect of the optimized implementation is that it doesn't support
applying reduce_agg to sorted inputs. I.e. one cannot use reduce_agg to compute an
equivalent of
SELECT a, array_agg(b ORDER BY b) FROM t GROUP BY 1
The array_agg computation depends on order of inputs. A comparable implementation
using reduce_agg would look like this:
SELECT a, reduce_agg(b, array[], (s, x) -> concat(s, array[x]), (s, s2) -> concat(s, s2) ORDER BY b) FROM t GROUP BY 1
To respect ORDER BY b, the reduce_agg would have to apply inputFunction to each
input value one at a time using a data-dependent loop from above. As we saw, this
is very expensive. The optimization we apply does not preserve the order of inputs,
hence, cannot support the query above. Note that
Presto doesn't
support applying reduce_agg to sorted inputs either.
One of the queries shadowed internally at Meta was much slower in Velox compared to presto(2 CPU days vs. 4.5 CPU hours). Initial investigation identified that the overhead is related to casting empty strings inside a try_cast.
In this blogpost I summarize my learnings from investigating and optimizing try_cast.
name total time try_cast(empty_string_col as int) 4.88s try_cast(valid_string_col as int) 2.15ms
The difference between casting a valid and invalid input is huge (>1000X), although ideally casting an invalid string should be
just setting a null and should not be that expensive.
Benchmark results after optimization:
name total time try_cast(empty_string_col as int) 1.24ms try_cast(valid_string_col as int) 2.15ms
The investigation revealed several factors that contributed to the huge gap, summarized in the points below in addition to
their approximate significance.
Error logs overhead.
Whenever a VeloxUserError is thrown an error log used to be generated, however those errors are expected to, (1) either get converted to null if is
thrown from within a try, (2) or show up to the user otherwise. Hence, no need for that expensive logging .
Moreover, each failing row used to generate two log message because VELOX_USER_FAIL was called twice. Disabling logging for user error helped save 2.6s of the 4.88s.
Throwing overhead.
Each time a row is casted four exception were thrown:
From within Folly library.
From Cast in Conversions.h, the function catch the exception thrown by Folly and convert it to Velox exception and throw it.
From castToPrimitive function, which catch the exception and threw a new exception with more context.
Finally, a forth throw came from applyToSelectedNoThrow which caught an exception and called toVeloxException
to check exception type and re-throw.
Those are addressed and avoided using the following:
When the input is an empty string, avoid calling folly by directly checking if the input is empty.
Remove the catch and re-throw from Conversions.h
Introduce setVeloxExceptionError, which can be used to set the error directly in evalContext without throwing (does not call toVeloxException).
Optimize applyToSelectedNoThrow to call setVeloxExceptionError if it catches Velox exception.
With all those changes throwing exceptions is completely avoided when casting empty strings. This takes the runtime down to 382.07ms,
but its still much higher than 2.15ms.
** Velox exception construction overhead.**
Constructing Velox exception is expensive, even when there is no throw at all! Luckily this can be avoided for try_cast, since
the output can be directly set to null without having to use the errorVector to track errors. By doing so the benchmark runtime goes
down to 1.24ms.
After all the changes we have the following performance numbers for other patterns of similar expressions
(much better than before but still can be optimized a lot).
try_cast(empty_string_col as int) 1.24ms 808.79 try_cast(invalid_string_col as int) 393.61ms 2.54 try(cast(empty_string_col as int)) 375.82ms 2.66 try(cast(invalid_string_col as int)) 767.74ms 1.30
All these can be optimized to have the same runtime cost of the first expression 1.24ms.
To do that two thing are needed:
1) Tracking errors for try, should not require constructing exceptions
The way errors are tracked when evaluating a try expression is by setting values in an ErrorVector; which is a vector of VeloxException pointers.
This forces the construction of a Velox exception for each row, but that is not needed (for try expressions) since only row numbers need to be
tracked to be converted eventually to nulls, but not the actual errors.
This can be changed such that errors are tracked using a selectivity vector. Its worth noting that for other expressions such as conjunct
expressions this tracking is needed, hence we need to distinguish between both.
This would help optimize any try(x) expression where x throws for large number of rows.
2)Use throw-free cast library
Avoiding throw and instead returning a boolean should allow us to directly set null in try_cast and avoid construction of exceptions completely.
While this is done now for empty strings, its not done for all other types of errors. Folly provides a non-throwing API (folly::tryTo) that can be tried for that purpose.
folly::tryTo. According to the folly documentation On the error path, you can expect tryTo to be roughly three orders of magnitude faster than the throwing to and to completely avoid any lock contention arising from stack unwinding.