Axiom: Composable Query Engines Built on Velox


Introduction
Axiom is a C++ library for building fully composable, high-performance query engines, built on top of Velox. Think of it as Lego for query processing — the pieces are compatible, but don't restrict how you put them together. Configure each layer, swap in your own components.
Today, users face significant friction moving between interactive queries, batch processing, streaming, and AI training data preparation — different engines, different semantics, different quirks. With Axiom, we can build all of these on a shared foundation, delivering consistent semantics across deployment modes.
The Current Landscape
Velox made execution composable — plugged into Presto via Prestissimo, into Spark via Gluten, into streaming and AI training workloads — and delivered 2-3x efficiency gains across the board. Velox also opened the door to GPU-accelerated query processing, with IBM and NVIDIA collaborating on GPU-native implementations of Velox operators for Prestissimo. But everything above execution remains monolithic and engine-specific.
Presto excels at interactive queries with streaming shuffle — optimized for latency. Spark excels at batch with durable shuffle — optimized for throughput. DuckDB provides a great single-node experience. But they all have different semantics. When a Presto query organically grows beyond Presto's limits, it must be rewritten in Spark SQL and migrated to Spark — a non-trivial, error-prone effort. Sapphire (Presto-on-Spark) exists specifically to work around this, running Presto SQL on Spark's durable execution, but it's inherently awkward — bolting one engine onto another.
Neither Presto nor Spark offers a practical local execution mode. Even basic SQL linting or running a query over in-memory VALUES requires going through the cluster — network calls, queuing, distributed execution. When iterating on analysis over the same data, trying to figure out the right way to slice and dice, every run goes through the cluster. Velox's AsyncDataCache can cache warm data in memory and SSD on Prestissimo workers, but that still requires distributed execution and depends on all cluster users working on the same warm data. There's no way to download your dataset locally, keep it in memory, and iterate fast on your own machine — DuckDB-style. Not possible with a monolithic distributed-only architecture.
Under the hood, the architectures are split along language boundaries. In Prestissimo, Java coordinator handles SQL parsing, optimization, and orchestrates distributed execution; C++ worker handles local execution. They connect via RPC — relatively clean, but connectors are split: metadata in Java, data reading in C++. Constant folding is another pain point — it happens in the coordinator (Java) but must produce results compatible with Velox execution, currently solved via a C++ sidecar, but clunky. In Gluten, Spark's Catalyst handles SQL parsing, DataFrame API, optimization, and orchestrates distributed execution; Velox handles local execution. They connect via JNI — more complex, harder to debug.
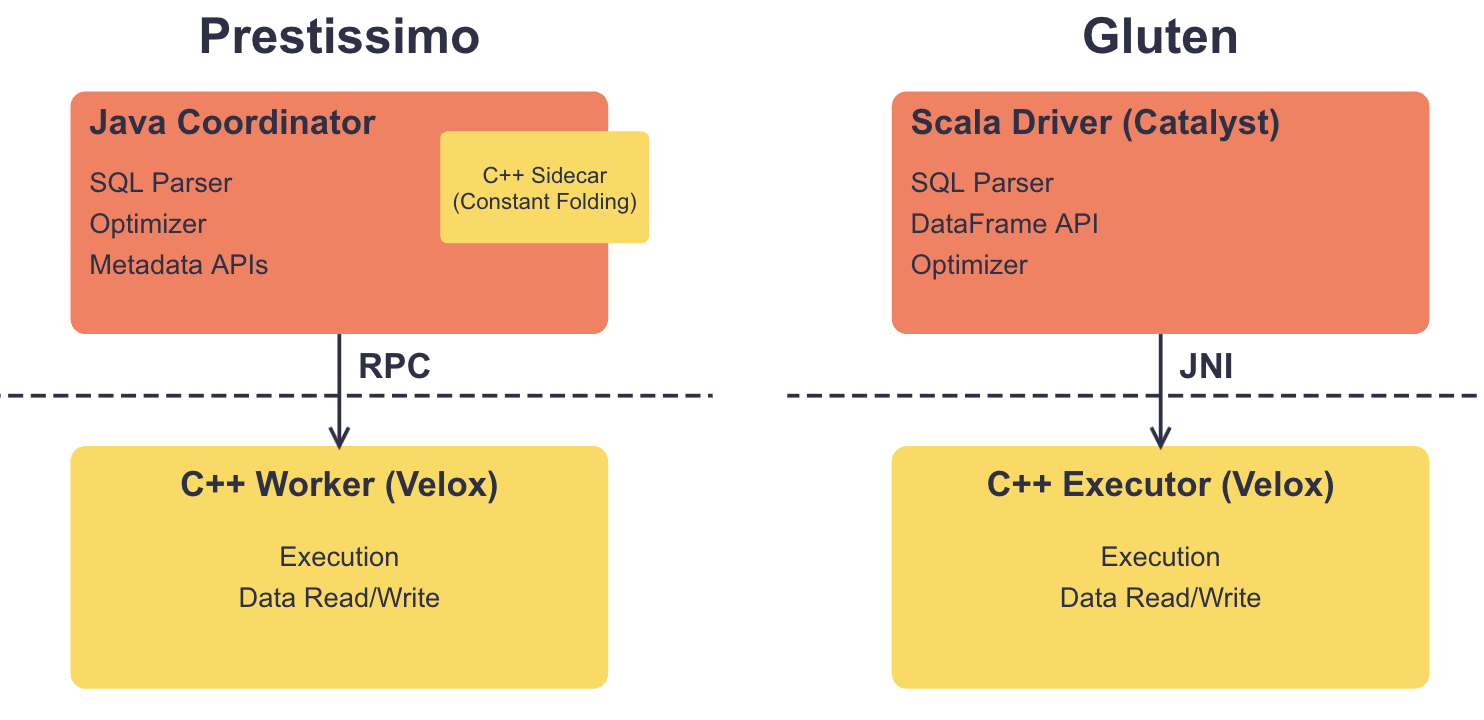
Both coordinators are monolithic — you can't add a DataFrame API to Presto, run Spark SQL on Presto's coordinator, or run Presto SQL on Spark.
Why hasn't anyone built a unified C++ stack before? We believe the major blocker has been the lack of a reusable C++ query optimizer. Optimizers are extremely hard to build, even with the use of AI. Catalyst is the closest thing to a reusable optimizer and has been widely adopted, but it's Java. So when Velox came along, the natural path was to plug it into existing JVM coordinators — building a C++ optimizer from scratch wasn't a realistic alternative. Until now.
Velox solved composability for execution. The layers above execution need the same treatment. That's the gap Axiom aims to fill.
How Axiom Solves This
Axiom decomposes the query engine into a set of independent, reusable components — frontends, optimizer, runtime, connectors, execution — connected by stable, engine-agnostic APIs. Each component can be swapped, extended, or composed independently. The key APIs are the logical plan (between frontends and the optimizer) and the physical plan (between the optimizer and the runtime). Axiom builds on Velox's extensible type system and function registry — the same types and function implementations are used by the optimizer and by execution, so semantics are consistent by construction. This is what makes it possible for different engines to plug in their own frontends or target different deployment modes — without forking or rebuilding the rest.
Composability requires crisp, clear contracts between components. Monolithic engines tend to treat these boundaries more fluidly, with code that sometimes crosses layer boundaries. This makes composability harder to build, but the resulting clarity pays off in extensibility and reuse.
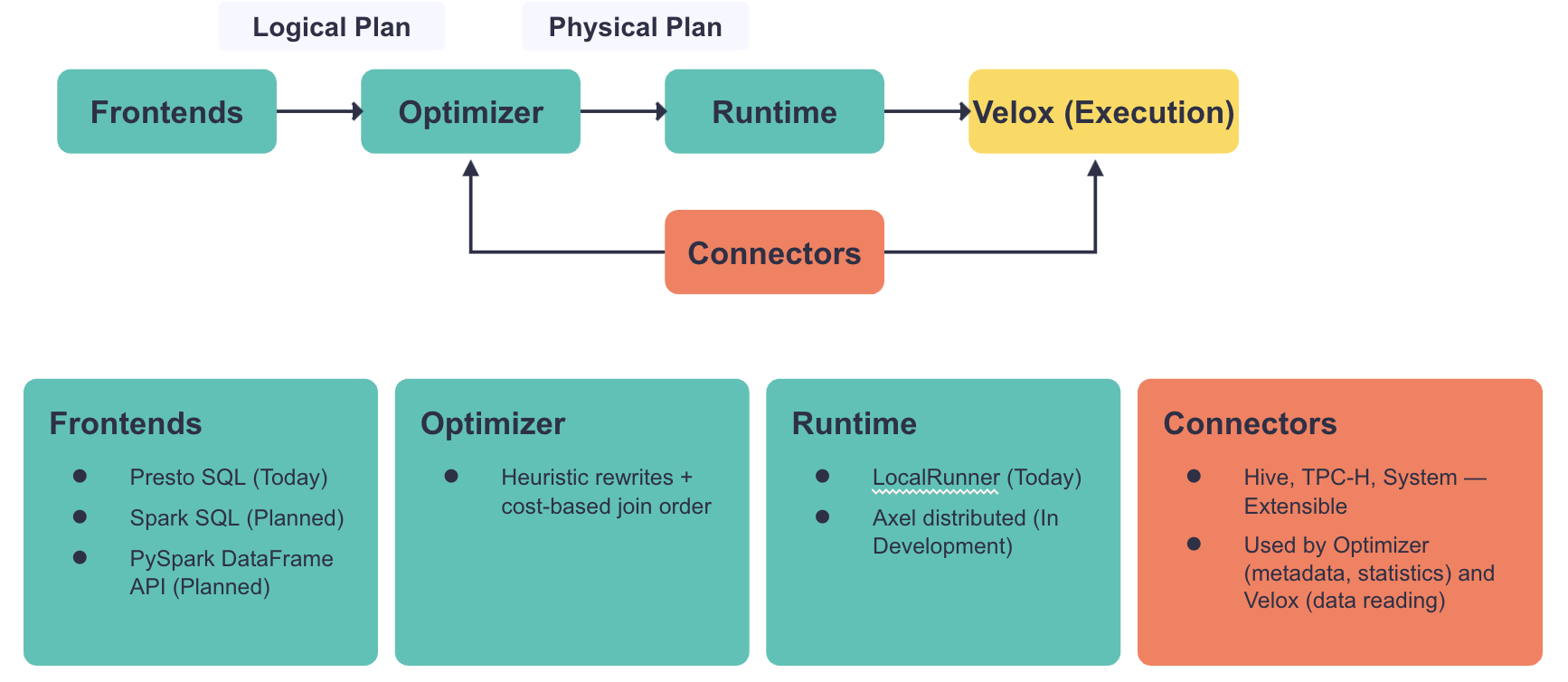
The logical plan is a fully resolved, typed, dialect-agnostic representation of the query — the contract between frontends and the optimizer. It describes what the query does, not how to execute it. The logical plan has 13 node types; Velox has 32. For example, there is a single logical JoinNode that specifies what to join, but the optimizer decides how — whether it becomes a HashJoinNode, MergeJoinNode, or NestedLoopJoinNode in Velox. Any frontend that produces a valid logical plan can use the same optimizer and execution stack. This is what makes it practical to add a Spark SQL parser or a PySpark DataFrame API without touching the rest of the system.
The optimizer directly uses Velox's function registry and expression evaluator — constant folding uses the same code path as query execution, with no integration overhead. The optimizer can also fold constant scalar subqueries by executing them in-process. It knows which Velox operators exist and can target them directly — for example, using counting joins for EXCEPT ALL. No need for a 2700-line conversion layer to translate between plan representations that don't map one-to-one.
The optimizer produces a physical plan (MultiFragmentPlan) — a set of Velox plan fragments connected by shuffle boundaries. The deployment topology is an input to the optimizer — shuffle costs affect join ordering and other plan decisions.
The runtime is the component that enables different deployment modes — it takes the physical plan and executes it locally in a single process, distributes with streaming shuffle for interactive latency, or distributes with durable shuffle for batch throughput. Axiom ships with a local execution runtime (LocalRunner) and a CLI that serves as a reference implementation illustrating how the components fit together. Axel, a separate initiative, is building a Presto-like distributed runtime on top of Axiom.
Connectors are also unified. Planning-time logic (metadata, statistics, partition pruning) and execution-time logic (data reading) live in the same language, unlike Prestissimo and Gluten where they are split across Java and C++.
Where We Are
Building a composable query processing stack is a long journey. Velox was a big step forward, but there are still many steps to take. We are still early, but the foundation is in place and the results so far are encouraging.
All TPC-H queries work end-to-end, producing optimal plans. We are actively migrating production workloads at Meta — the optimizer and execution stack are handling real queries at scale, not just benchmarks.
Axiom includes an interactive CLI that lets developers and users run SQL locally against TPC-H, Hive, or in-memory data. This has become a popular tool for rapid prototyping and testing — users love sub-second SQL linting and validation without waiting for a cluster round-trip.
We are also extending Presto SQL with user-friendly features inspired by DuckDB: FROM-first syntax, trailing commas, SELECT * EXCLUDE/REPLACE, and more (see Presto SQL Extensions).
The composable architecture is proving itself beyond the original use case. The graph query team built a Cypher frontend that produces Axiom's logical plan and leverages the optimizer's cost-based join reordering for graph pattern matching — demonstrating that the logical plan and optimizer work for non-SQL languages. Both the streaming and AI training data processing teams adopted Axiom's Presto SQL parser to offer a SQL interface alongside their existing Python APIs.
Get Involved
Velox made execution composable and delivered massive efficiency gains. Axiom extends that same vision to the full query processing stack. The pieces are there — come help us put them together.
We want to partner with the community to tackle what's next. A Spark SQL parser and PySpark DataFrame API would close the gap between Presto and Spark users. There is room for more Friendly SQL features. The optimizer can become more extensible and add support for index and merge joins. Axel will benefit from durable shuffle to enable batch workloads with the fault tolerance that Spark users expect. And the connector ecosystem is ready to grow.
- GitHub: facebookincubator/axiom