FlatMapVector Adoption for Scaling High-Performance AI/ML Data Pre-Processing





Context
At Meta, features used for AI use cases are largely combined and stored within warehouse tables as map columns because frequent access to and manipulation of these features can scale poorly if modelled as top-level columns, which would result in extremely wide tables and frequent schema changes. Thus, to provide maximum flexibility, features are modeled as maps.
In a traditional columnar layout, map columns are typically represented in-memory by a few data streams. The diagram below illustrates an example dataset. Two main buffers or streams are allocated for map keys and values. Additional buffers are used for null flags and map offsets or lengths (note that map keys are non-nullable):
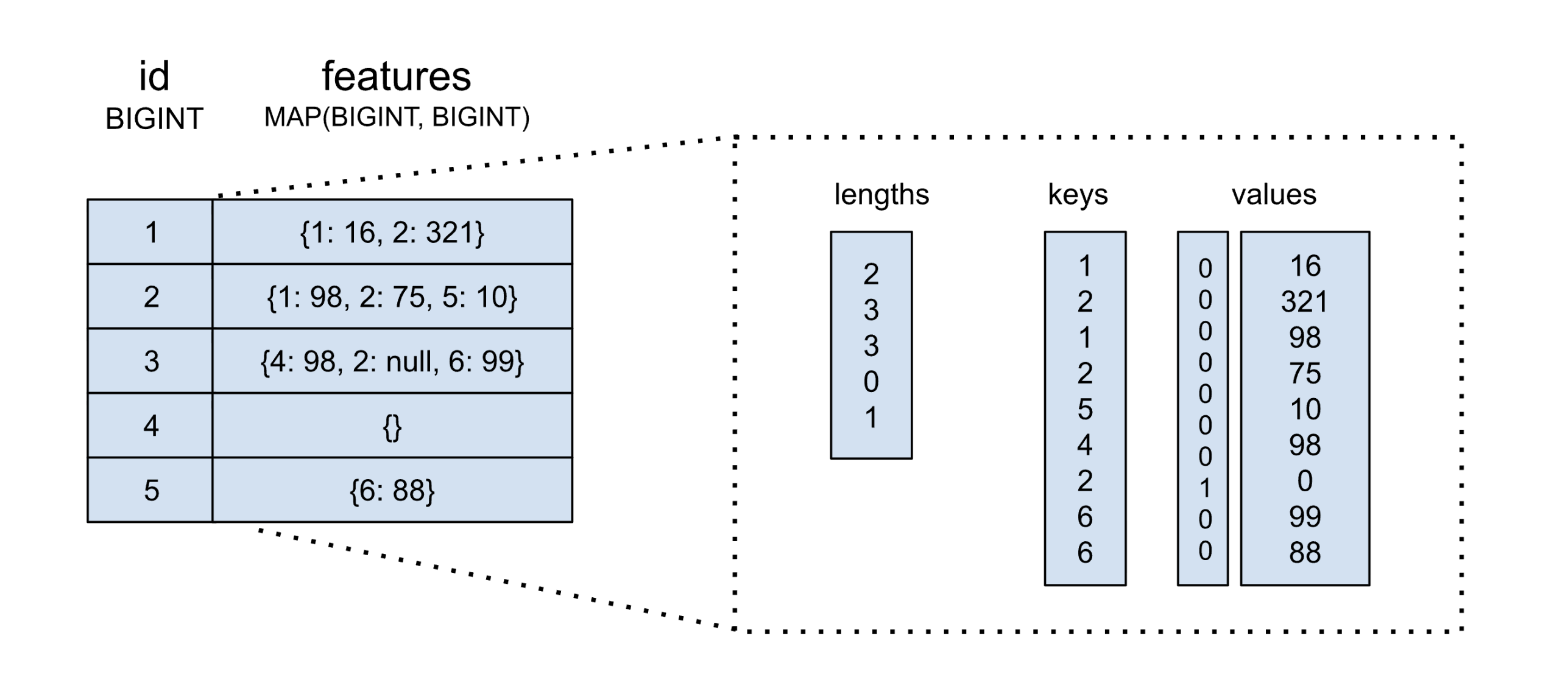
While simple, fast, and efficient, common map operations, like feature projection, cannot be trivially executed without materializing the entire map. For extremely wide tables where only a subset of map keys are read, like in many AI workloads, reading and decoding the entire map makes these operations impractical at scale.
Flat Maps
To enable efficient map transformations that operate over particular map keys, Meta uses the "flat map" map encoding. The term "flat maps" refers to a logical encoding that stores map data using value streams grouped by key. The diagram below reuses the same example above, but illustrates the "flat map" encoding. Notice the individualized value streams, identified by their unique key value.
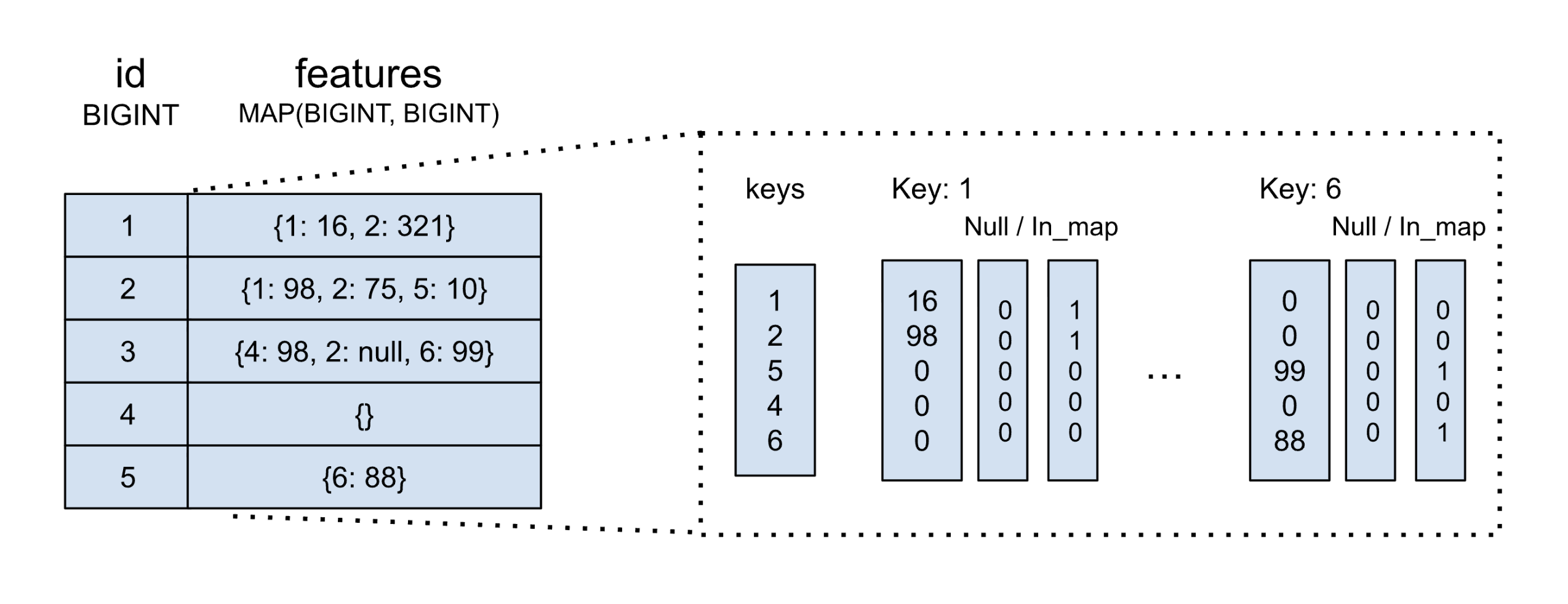
Flat maps provide several fields: a unique set of keys, and a list of value streams and "in map" and "null" buffers. Value streams and buffers are sized to match the rows in the table.
Flat maps also use a "null" bitmap buffer, like traditional maps; however, unlike traditional maps, flat maps also provide an "in map" buffer. This additional bitmap is used to identify whether or not a particular key-value pair exists in a particular row.
Since streams and buffers are grouped by key, certain map operations like key filtering and projection do not require full vector materialization. The drawback, however, is worse storage efficiency due to fragmented, full-length data streams.
Flat Maps at Meta
"Flat map" encoding is not a novel concept and is already used extensively at the storage layer in many training tables at Meta, but prior to a recent effort, no equivalent in-memory layout existed in Velox's compute framework.
To avoid flat map to map conversion overhead, certain engines like DPP and Spark awkwardly cast flat maps as row types, which solves the problem, but severely limits training data context and ability to leverage map functions. Moreover, other compute engines like Presto are unable to leverage this workaround since the implicit conversion from MAP to ROW results in irreconcilable semantic differences.
To improve the efficiency of our AI training workloads, we have designed and implemented a new Velox vector type to our data processing framework that provides a native in-memory flat map encoding for Velox map types: FlatMapVectors.
Pilot Use Cases
To pilot our first internal FlatMapVector use cases, we targeted two Spark use cases: feature injection and feature reaping. Feature injection refers to the process of adding new features to map columns, while feature reaping does the opposite, removing features.
To support these use cases, full-stack support would be required to support our new vector type. Some of this work included adding new readers and writers to our DWRF and Nimble IO suite and adding FlatMapVector support to our map UDFs. In theory, the former should provide immediate wins by eliminating conversion overhead, but how do end-to-end performance numbers look in practice? Let's start by examining two production tables onboarded to our feature reaping and injection pipelines. These two tables provide a good sample of our workloads:
Table 1 (1,000 rows)
| Metric | MapVector | FlatMapVector | Improvement |
|---|---|---|---|
| TableScan Input | 26.22 GB | 34.96 MB | 768x more compact |
| TableScan CPU Time | 9.52s | 1.85s | 5.1x faster |
| TableScan Wall Time | 11.30s | 3.75s | 3.0x faster |
| TableScan Allocs | 1,254,358 | 213,629 | 5.9x fewer |
| TableWrite CPU Time | 19.82s | 14.03s | 1.4x faster |
| TableWrite Wall Time | 23.07s | 17.37s | 1.3x faster |
| TableWrite Output | 212.01 MB | 212.02 MB | same |
Table 2 (100K rows)
| Metric | MapVector | FlatMapVector | Improvement |
|---|---|---|---|
| TableScan Input | 19.87 TB | 15.20 GB | 1,338x more compact |
| TableScan CPU Time | 6h 52m | 23m 50s | 17.3x faster |
| TableScan Wall Time | 7h 3m | 28m 49s | 14.7x faster |
| TableScan Allocs | 4,207,241,070 | 196,178,311 | 21.4x fewer |
| TableWrite CPU Time | 2h 59m | 1h 46m | 1.7x faster |
| TableWrite Wall Time | 3h 9m | 1h 54m | 1.7x faster |
| TableWrite Output | 66.27 GB | 65.44 GB | ~same |
As expected, without high conversion overhead, reading and writing is significantly improved, producing 5x and 17x read latency improvements for both of our tables, respectively. We also see astronomical memory savings, quite literally reducing magnitudes of consumed resources in either case.
Moreover, it seems that the larger consumed data becomes, the wider the performance gaps grow between the vector types, demonstrating the serious consequences of map conversion at scale. Are these performance wins enough to see end-to-end results? Let's now examine how our vectors behave in-memory, starting with feature projection used heavily in feature injection. The below benchmarks feature projection over various mixed feature counts:
| Scenario (Distinct Keys, average Keys per row) | MapVector | FlatMapVector | Speedup |
|---|---|---|---|
| D=10, K=5 | 129ms | 0.6ms | 215x |
| D=50, K=10 | 190ms | 0.6ms | 327x |
| D=50, K=10 | 269ms | 0.6ms | 453x |
| D=200, K=20 | 488ms | 0.6ms | 820x |
As expected, FlatMapVector provides constant lookup due to grouped value streams. Meanwhile, MapVector grows with volume size due to hash-lookup. Feature projection is a clear win.
Filtering, on the other hand, is a little more nuanced. FlatMapVectors suffer from value filtering due to fragmented value streams; however, because feature reaping uses feature (key-only) predicates, we still see some improvement:
| Scenario (Distinct Keys, average Keys per row) | Filter (% of keys filtered out) | MapVector | FlatMapVector | Speedup |
|---|---|---|---|---|
| D=10, K=5 | large (90%) | 58ms | 22ms | 2.6x faster |
| half (50%) | 51ms | 13ms | 4.0x faster | |
| narrow (10%) | 52ms | 5.5ms | 9.4x faster | |
| D=50, K=10 | large (90%) | 104ms | 104ms | 1.0x (tie) |
| half (50%) | 92ms | 66ms | 1.4x faster | |
| narrow (10%) | 79ms | 24ms | 3.3x faster | |
| D=200, K=20 | large (90%) | 211ms | 533ms | 2.6x slower |
| half (50%) | 190ms | 302ms | 1.6x slower | |
| narrow (10%) | 178ms | 131ms | 1.4x faster | |
| D=500, K=50 | large (90%) | 531ms | 1.48s | 2.8x slower |
| half (50%) | 478ms | 863ms | 1.8x slower | |
| narrow (10%) | 369ms | 260ms | 1.4x faster |
The more selective the key filter, the better FlatMapVector performs. The cost scales with the number of matching channels. For large filters (90%), copying the majority of value streams and buffers can be quite expensive. This is a known issue exposed by our in-progress support for partition merge; however, narrow filters more closely represent our production feature reaping workloads, where FlatMapVector consistently wins.
So What?
Although only first targeting specified use cases, the introduction of FlatMapVectors into Velox's compute framework represents a demonstrable step forward in scaling high-performance AI data pre-processing. Quite literally, both feature reaping and feature injection see magnitudes of performance increases by avoiding map conversion overhead and significant in-memory feature projection and filtering speedup. Leveraging FlatMapVectors for scaling AI workloads appears to no longer be negotiable.
We already have several workstreams to continue to support FlatMapVectors across multiple warehouse use cases. For one, we want to continue onboarding new Spark workloads, which as demonstrated above provides tangible wins for our internal Spark users. Additionally, we want to completely descope the ROW type workaround for flat maps in engines like DPP. Both this and support in Presto necessitate flat map encoding implementations in map UDFs, which is a non-trivial task. Eventually, we'd like FlatMapVectors to be the default way to access data written to storage as flat maps, across all Velox-supported engines.