Nimble Cluster Index: Efficient Indexed Lookups on Columnar Data






Introduction
Analytical data lakes excel at full-table scans but struggle with point lookups. Key-value stores handle point lookups efficiently but cannot serve analytical queries. What if a single file format could serve both workloads?
Nimble's Cluster Index bridges this gap. It is a lightweight, hierarchical index structure embedded directly inside Nimble columnar files. It enables O(log n) point lookups and range scans on sorted data — without a separate index file, without an external service, and without sacrificing Nimble's columnar scan performance.
We have integrated the cluster index with Presto for analytical index joins and are actively integrating with ZippyDB for prefix key scans — both powered by the same underlying index structure, served through Velox.
Motivation
Consider a common pattern in data warehousing: a large fact table needs to be joined with a dimension table on a key column. Traditional hash joins materialize both sides into memory. For selective lookups — where the probe side touches only a fraction of the build side — this is wasteful.
Index joins solve this: for each probe key, look up only the matching rows in the build table, skipping everything else. But this requires an efficient index on the build-side file.
Similarly, in ML training data serving, workloads need prefix key scans with column projection — e.g., fetching a user's event history while reading only the features a model needs. Without an index, this requires scanning entire stripes — unacceptable at serving latency.
The cluster index addresses both use cases with a single, unified design.
File Layout
The cluster index is stored as a FlatBuffer-serialized optional section in the Nimble file footer. No separate index file is needed — the index lives alongside the data it references.
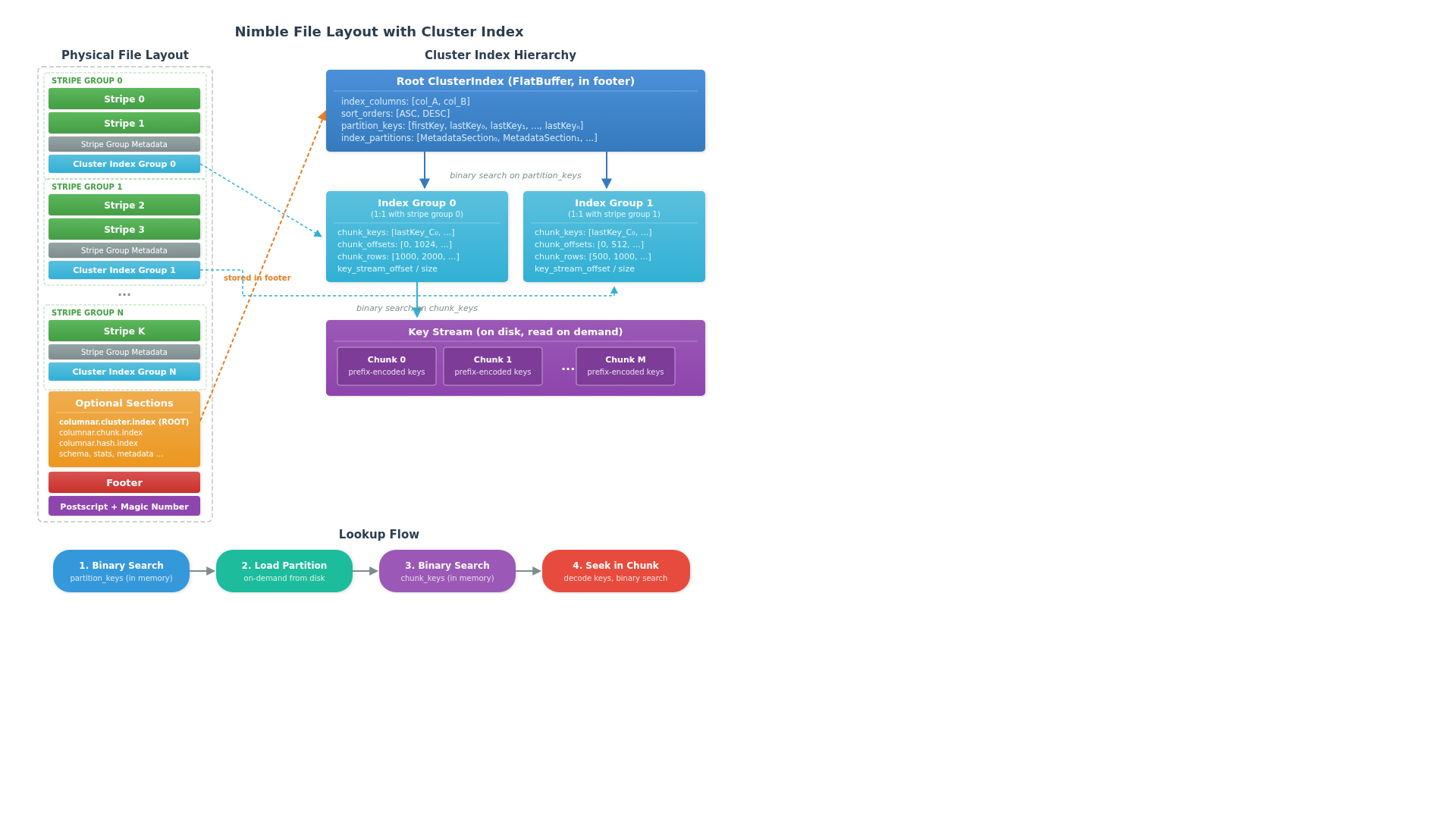
Hierarchical Structure
The index is organized as a three-level hierarchy designed to minimize I/O:
Level 1: Root ClusterIndex. The root is a FlatBuffer table embedded in the file footer's optional sections. It contains the index column names, sort orders, and an array of partition_keys — the boundary keys for each index group. Since this metadata is loaded when the file is opened, the first level of binary search requires zero additional I/O.
Level 2: Index Groups. Each index group corresponds 1:1 to a stripe group and contains metadata for the chunks within it: chunk_keys (boundary keys per chunk), chunk_offsets, and chunk_rows (accumulated row counts). Index groups are written inline after each stripe group and loaded on demand — only the group(s) that could contain the lookup key are read from disk.
Level 3: Key Stream Chunks. The actual encoded keys live in the key stream, divided into fixed-size chunks. Each chunk stores keys using prefix encoding (with a configurable restart interval) for compact representation. Only the specific chunk(s) identified by the group-level binary search are read and decoded.
Key Encoding
Multi-column index keys are serialized into a single byte-comparable binary string using Velox's KeyEncoder. The sort order (ascending or descending) for each column is baked into the encoding, so a simple byte comparison on the encoded key correctly handles multi-column composite keys with mixed sort orders.
Lookup Flow
A lookup proceeds through the hierarchy:
- Binary search on
partition_keys— identifies which index group(s) could contain the target key. This is pure in-memory computation — no I/O. - Load index group metadata — reads the matching group's FlatBuffer from disk (cached for repeated lookups).
- Binary search on
chunk_keys— narrows down to specific chunk(s) within the group. Again, in-memory only. - Seek within chunk — reads and decodes the key stream chunk, then binary searches the materialized keys to find the exact row range.
The result is a set of file-level row ranges — contiguous for both point lookups and range scans since the data is sorted by the index key.
The key design insight is that the common case — eliminating entire index groups — requires no disk I/O at all. Only when a group is a candidate does the system incur reads, and even then, only the specific chunk within that group is loaded.
Beyond ClusterIndex: Hash and Sorted Indices
While the cluster index is optimized for sorted data, Nimble also supports two additional index types for unsorted data:
HashIndex — O(1) amortized point lookups using a hash table with optional Bloom filter. The Bloom filter follows the Parquet split-block design (256-bit blocks, 8 hash probes per block, xxHash64) for cache-friendly probabilistic filtering before accessing the hash buckets.
SortedIndex — A secondary index that maintains a separately sorted copy of the keys alongside their original row IDs. Each entry in the sorted key stream is a composite encoded_key || fixed_width_row_id, enabling binary search while carrying the row ID inline. This supports both point lookups and range scans on unsorted data.
All three index types implement a unified IndexLookup interface with PointLookup and RangeScan modes, and are discovered through the DenseIndexRegistry which transparently selects the best available index for a given set of columns.
Integration with Presto
We integrated the Nimble cluster index with Presto's native execution engine (Prestissimo) through Velox's IndexLookupJoin operator.
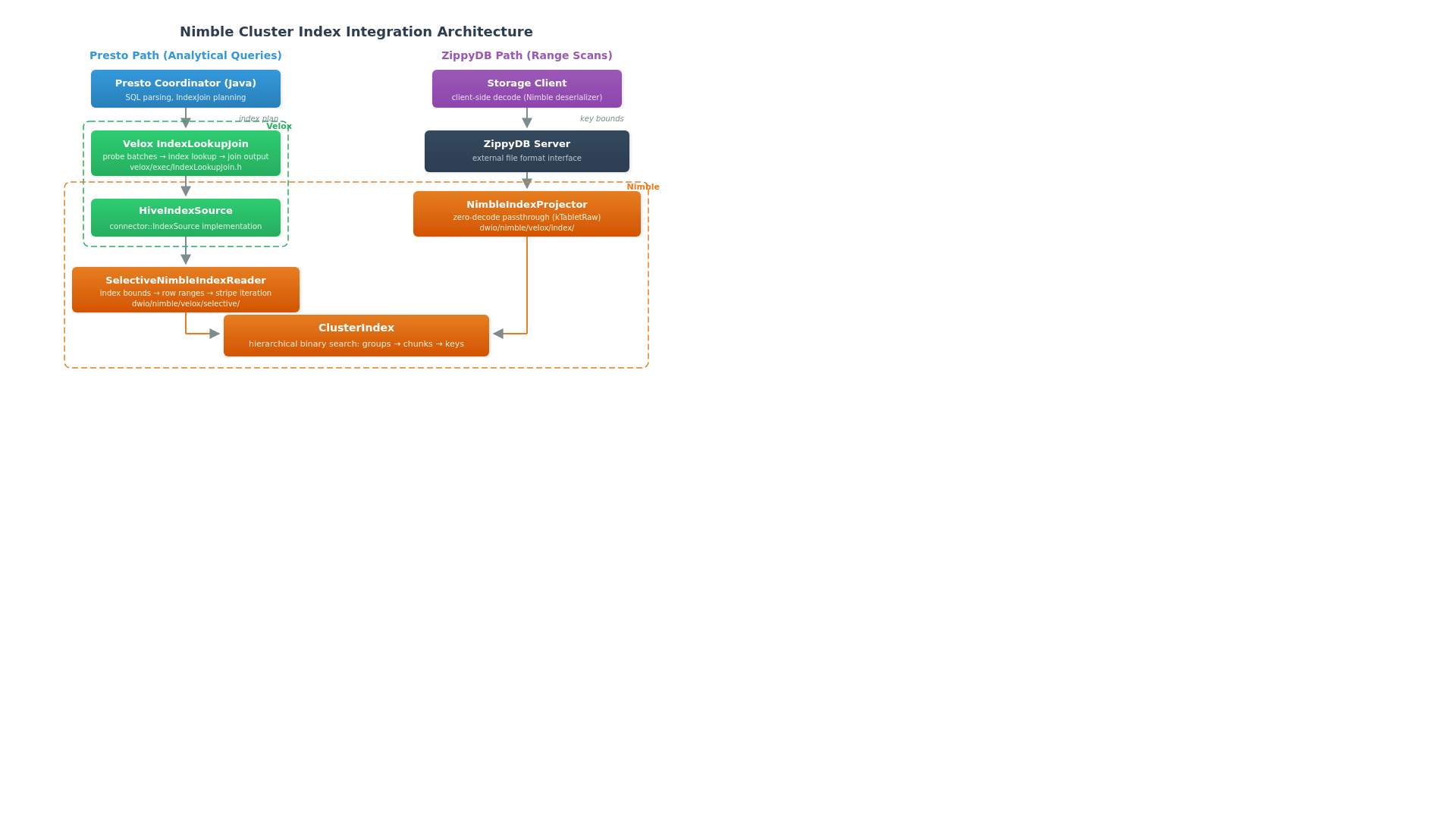
The Execution Path
The Presto integration flows through several layers:
Presto Coordinator (Java) — The query optimizer recognizes index join opportunities and generates an IndexJoinNode in the query plan, with planner rules for lookup variable extraction, non-equal join condition support, and index join session properties.
Velox IndexLookupJoin — The execution operator receives probe-side input batches and performs index lookups against the cluster indexed table. It projects lookup columns from each probe batch, detects and excludes null keys, and calls into the connector's IndexSource for the actual lookup. For left joins, unmatched probe rows are emitted with null values for the lookup columns. The operator pipelines multiple probe batches to overlap lookup I/O with processing.
HiveIndexSource — Implements Velox's connector::IndexSource interface for Hive tables. The coordinator retrieves index metadata from the Hive metastore (declared via the indexed_by DDL table property) and passes it to the worker through the table handle.
SelectiveNimbleIndexReader — The Nimble-specific implementation of Velox's IndexReader interface. It converts index bounds into encoded key bounds, calls ClusterIndex::lookup() to resolve file-level row ranges, then maps those ranges to stripes and iterates through them using the selective column reader with precise seekTo() operations.
A notable design detail in the reader is how it handles overlapping row ranges from multiple lookup requests. When no additional filter is present, it merges overlapping ranges for efficient bulk reads. When a filter is present, it splits ranges into non-overlapping segments so that filtered output can be correctly attributed back to the originating request.
Usage
With the integration in place, users can create Nimble tables with a cluster index and query them with index joins:
-- Create a table with cluster index on the key column
CREATE TABLE dimension_table (
key_col BIGINT,
value_col VARCHAR,
...
) WITH (
format = 'NIMBLE',
indexed_by = '["key_col"]'
);
-- The optimizer automatically chooses index join when beneficial
SELECT f.*, d.value_col
FROM fact_table f
JOIN dimension_table d ON f.key_col = d.key_col
WHERE f.date = '2026-04-27';
Integration with ZippyDB
We are actively integrating the cluster index with ZippyDB to serve point lookup workloads. The integration uses a fundamentally different strategy than the Presto path, optimized for serving latency rather than analytical throughput.
Server-Side Zero-Decode Projection
The key innovation in the ZippyDB path is the NimbleIndexProjector, which implements a zero-decode passthrough strategy. Instead of decoding Nimble-encoded data into Velox vectors on the server (as the Presto path does), it extracts the raw encoded stream bytes and sends them directly to clients via the Nimble serializer — without decoding or re-encoding. The client deserializes and decodes locally. This design shifts the CPU cost of decoding from the centralized lookup service to the distributed clients — critical for a serving system where the server is the bottleneck.
The projector uses the same ClusterIndex::lookup() for key-to-row-range resolution, but then takes a completely different serialization path. It builds per-stripe results by copying raw stream bytes directly from the tablet's encoded streams, with no intermediate decode/re-encode step.
Design Tradeoffs
| Aspect | Presto Path | ZippyDB Path |
|---|---|---|
| Decode location | Server (Velox vectors) | Client (raw bytes) |
| Output format | RowVector | Nimble serializer |
| Filter support | Full pushdown | Key-only |
| Optimized for | Throughput | Latency |
| CPU bottleneck | Distributed workers | Centralized server |
Performance Characteristics
The hierarchical design provides several performance properties:
Minimal I/O amplification. A point lookup on a file with millions of rows typically requires 2 disk reads: one for the index group metadata and one for the target key stream chunk. The root-level group search is free — it's already in memory from the file open.
Bounded memory overhead. Only the root FlatBuffer is kept in memory permanently. Index group metadata and key stream chunks are loaded on demand and can be cached or evicted independently.
Write-time cost is low. The index is built incrementally during writes — keys are encoded as a byte stream and chunked as rows are flushed. The root-level partition metadata is assembled at file close. There is no post-write index building step.
Composability with columnar scans. The cluster index produces row ranges, not decoded values. These row ranges feed directly into the selective column reader's seekTo() mechanism, which uses the separate ChunkIndex (a position-to-offset mapping per stream) to skip efficiently within stripes. The index lookup and the columnar read are cleanly separated — the index narrows the search space, and the columnar reader handles the actual data extraction.
What's Next
We are continuing to expand the cluster index ecosystem:
- ZippyDB production integration — completing the end-to-end integration with ZippyDB's serving layer.
- Adaptive index selection — automatically choosing between cluster, hash, and sorted indices based on query patterns and data characteristics.
- Vector search index — exploring embedding FAISS-based approximate nearest neighbor indices inside Nimble files, co-locating vector search with columnar data so one indexed file serves analytical queries, training pipelines, and retrieval workloads.
Acknowledgements
Thanks to the Velox, Nimble, and Presto teams at Meta for the foundational infrastructure and integration work that makes this possible.